 网硕互联帮助中心
网硕互联帮助中心【导语】作为IT基础设施服务领域的从业者,我们在日常工作中发现,AI服务器的智能化运维能力正在重塑传统IDC的管理模式。本文将以DeepSeek系列服务器为例,分享智能算力设备在真实运维场景中的创新应用。
一、传统服务器集群的运维痛点
在数据中心日常运维中,我们经常面临以下技术挑战:
二、DeepSeek的智能化运维实践
2.1 动态资源调度优化
通过集成NVIDIA DCGM工具链,我们实现了:
- 实时采集每块A100显卡的SM利用率(采样周期缩短至5s)
- 构建容器化的弹性资源池,动态调整K8s调度策略
- 实测将GPU平均利用率从58%提升至82%

2.2 智能硬件诊断系统
DeepSeek的BMC模块新增了以下监测维度:
2.3 能效优化方案
部署智能散热系统后:
- 基于机柜微环境温度动态调节风扇转速
- 采用强化学习算法优化冷通道气流组织
- 实现全年PUE值稳定在1.25以下
三、典型应用场景解析
案例:某自动驾驶研发团队
- 需求:需要弹性扩展的A100算力支持模型训练
- 解决方案:
- 部署DeepSeek服务器集群(8节点/32卡)
- 配置Slurm作业调度系统
- 集成Prometheus+Grafana监控平台
- 成果:
- 模型迭代周期从72小时缩短至18小时
- 硬件故障响应时间<15分钟
- 综合运维成本降低35%
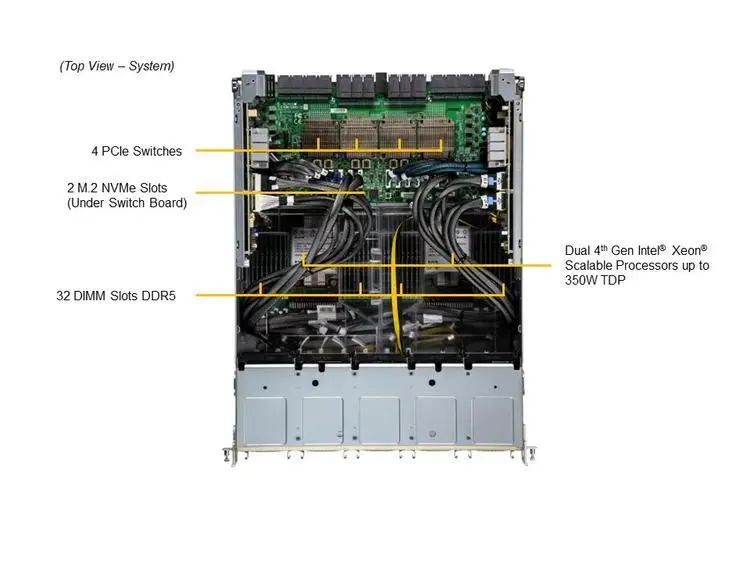
四、技术选型建议
对于考虑部署AI服务器的团队,建议关注:
在信安IT租赁平台的运维实践中,我们验证了DeepSeek系列服务器在自动化运维方面的技术优势。其开放的API接口和模块化设计,特别适合需要快速部署弹性算力的研发团队。
五、行业发展趋势展望
IDC最新报告显示,到2025年智能运维(AIOps)在数据中心的市场渗透率将达到45%。未来我们将重点关注:
【结语】AI服务器的智能化特性正在重构IT基础设施的运维范式。作为技术从业者,我们需要持续关注硬件层面的创新如何赋能软件生态的发展。本文涉及的运维实践,已在信安IT租赁平台的技术验证环境中完成POC测试,相关技术细节欢迎通过CSDN私信交流。




评论前必须登录!
注册