 网硕互联帮助中心
网硕互联帮助中心
一、引言
假如有10W 预算,打算搭建深度学习服务器,该如何分配资金,让各硬件组件协同发力,达到最优性能呢?本文不仅给你具体的案例,还有相关的配置思路。
二、需求分析
在动手配置服务器前,得先明晰自己的深度学习任务需求,毕竟不同任务对硬件的倚重程度大不一样。要是主要搞图像识别,像目标检测、图像分类这些,那对显卡的算力要求就极高。因为深度学习模型训练时,要处理海量图像数据,显卡负责的矩阵运算可是大头,强劲的 GPU 能大幅缩短训练时间,让你更快看到模型成效。像基于卷积神经网络(CNN)的图像识别模型,在训练中需要频繁进行卷积、池化等运算,这对显卡的并行计算能力是个大考验,要是显卡性能欠佳,训练过程会慢得让人抓狂。
要是专注于自然语言处理,像文本分类、机器翻译之类,虽说 GPU 同样关键,但 CPU 和内存的作用也不容小觑。自然语言处理常涉及大规模文本数据的预处理、词向量生成等操作,这时候多核高频的 CPU 就能大显身手,高效处理这些顺序执行的任务。
所以,先审视自己手头的深度学习项目,是图像主导、文本主导,还是二者兼顾,确定好对显卡、CPU、内存等硬件的性能侧重点,后续配置才能有的放矢,把预算花在刀刃上。
三、核心硬件选购要点
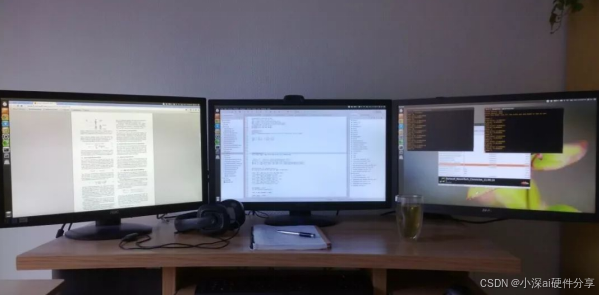
(一)显卡:深度学习的算力担当
在深度学习领域,显卡堪称核心中的核心,其算力直接决定模型训练的速度。当下,英伟达的 GeForce RTX 4090 无疑是热门之选,基于 Ada Lovelace 架构,拥有 16384 个 CUDA 核心,24GB GDDR6X 显存,显存位宽 384bit,显存频率高达 21000 MHz,单精度浮点性能超强,无论是图像识别、目标检测,还是复杂的自然语言处理任务,都能展现出卓越的计算效率,大幅缩短训练时间。像基于 Transformer 架构的大型语言模型训练,RTX 4090 能让训练周期从以周为单位骤减到以天计算,让科研人员更快迭代模型,抢占科研先机。
要是预算充足,追求极致性能,像英伟达的专业计算卡 Tesla V100 等更是不二之选。Tesla V100 基于 Volta 架构,5120 个 CUDA 单元、640 个张量核心,双精度浮点计算能力可达 7.8 TFLOPS,单精度 15.7 TFLOPS,混合精度 125 TFLOPS,搭配 32GB HBM2 显存,带宽高达 900GB/s,在处理大规模深度学习任务时,数据读取、计算一气呵成,稳定性极高,广泛


评论前必须登录!
注册