 网硕互联帮助中心
网硕互联帮助中心由于图片和格式解析问题,可前往 阅读原文
最近DeepSeek简直太火了,频频霸榜热搜打破春节的平静,大模型直接开源让全球科技圈都为之震撼!再次证明了中国AI的换道超车与崛起
DeepSeek已经成了全民ai,使用量也迅速上去了,加上对面半球对ds服务器的攻击导致现在使用起来动不动就崩溃

那么如何解决这个问题呢❓
上一篇《DeepSeek搭建私有GPT》讲了结合FastGPT与OneAPI直接调用 deepseek api 来本地部署自己的gpt,一定程度上也可以缓解使用对公的gpt,但此种方式在用户调用过多时也会出现问题,毕竟算力在云端,目前官方也停止了充值,这也反映了当前问题
:::warning 小贴士 文章中涉及到的示例代码你都可以从 这里查看 ,若对你有用还望点赞支持 :::
当然DeepSeek开源了多个大模型当然也可以本地进行部署,虽然没有在线模型那么强大,但也足够使用了。相较于api调用或者公开的gpt来说,本地部署可以不需要联网、数据隐私更安全,响应更快更方便
来看怎么部署
Ollama
Ollama 是一个开源的机器学习框架,旨在简化 AI 模型的训练和部署过程,Ollama 提供了简洁的 API 和直观的命令行界面,让用户能够快速开始训练和部署模型,无需复杂的配置;是本地运行大模型的利器(对小白非常友好)
安装Ollama
Ollama支持linux、MacOS、Windows平台的安装,打开官网页面直接点击Download按钮下载会自动下载适合自己系统的安装包
安装完后打开终端,输入ollama -v正常情况下会输出版本信息:
➜ ollama -v
ollama version is 0.5.7
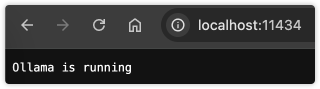
除此之外也支持api调用,访问http://localhost:11434/会返回Ollama is running
下载大模型
Ollama安装完毕后就可以下载大模型了,Ollama支持很多厂商的模型,可以在官网https://ollama.com/search查看
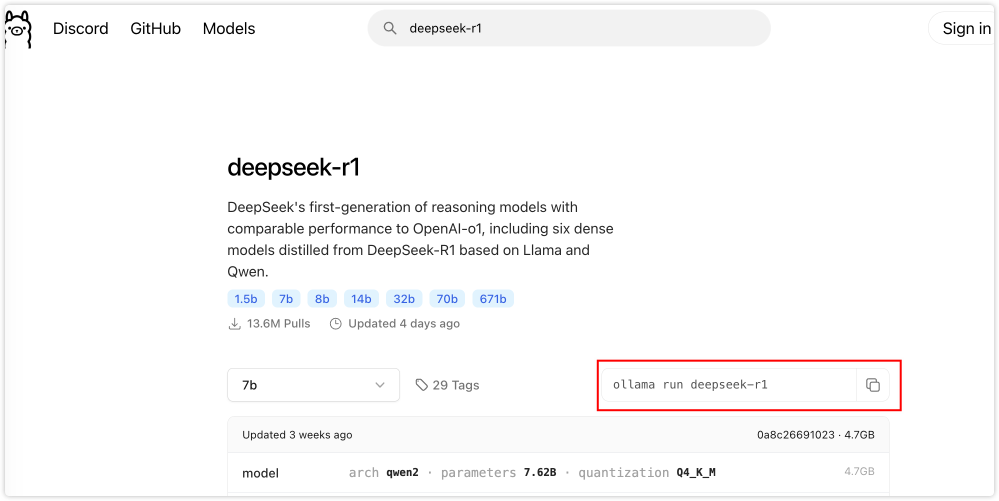
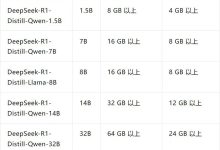
这里搜索deepseek安装deepseek-r1模型,左侧有对应的标签,默认是7b体量,读者需要根据自己机器情况安装合适的体量模型
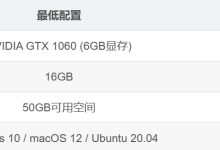
本人机器MacOS配置如下
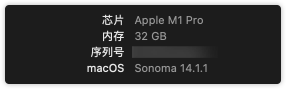
跑14b也绰绰有余,7b相对14b来说有很多噪点,这里就直接7b了
打开终端,直接输入:
ollama pull deepseek-r1:14b
是不是感觉命令和docker很像,是的Ollama的大多数命令都和docker类似,可以在终端输入ollama查看
回车后就开始拉取文件了,整体时间受模型的大小网速影响

运行模型
拉取完后就可以使用了,可以先输入以下命令输出本地所有的模型
➜ ollama list
NAME ID SIZE MODIFIED
deepseek-r1:14b ea35dfe18182 9.0 GB 3 minutes ago
deepseek-r1:7b 0a8c26691023 4.7 GB 39 hours ago
llama3.2:latest a80c4f17acd5 2.0 GB 2 days ago
运行模型:
➜ ollama run deepseek-r1:14b
>>> Send a message (/? for help)
这里本人试下青椒炒蛋教程:
除此之外也可以使用REST API进行调用,这里我们接着使用上一篇使用到的Nodejs代码:
import readline from "readline";
import axios from "axios";
const API_URL = "http://localhost:11434/api/chat";
const MODEL = "deepseek-r1:14b";
async function generateMessage(inputText) {
const completion = axios({
url: API_URL,
method: "POST",
data: {
model: MODEL,
messages: [{ role: "user", content: inputText }],
stream: true,
},
responseType: "stream",
});
completion.then((res) => {
res.data.on("data", (chunk) => {
process.stdout.write(JSON.parse(chunk.toString()).message.content || "");
});
res.data.on("end", () =>
console.log("\\n\\n(以上是我的回答,请合理参考,祝您生活愉快!)\\n\\n")
);
});
}
function bootstrap() {
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
});
console.log(
"我是一个智能助手,你可以向我提问任何问题,我将尽力回答。🌈🌈\\n\\n"
);
rl.on("line", async (input) => {
if (input === "q") {
rl.close();
return;
}
generateMessage(input);
});
rl.on("close", () => {
console.log("\\nBye!");
process.exit(0);
});
}
try {
bootstrap();
} catch (error) {
console.error(error);
process.exit(1);
}
来看下效果:

注意‼️ 如果使用ip进行调用的话,可能会访问不通,可执行以下命令后重启ollama即可
launchctl setenv OLLAMA_HOST "0.0.0.0"
OpenUI
来看看和界面应用结合使用,这里使用 OpenUI 开源免费的界面,类似于ChatGPT那种使用非常简单
这里直接使用docker部署:
docker run -d -p 3000:8080 –add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data –name open-webui ghcr.io/open-webui/open-webui:main
初次运行会下载需要的镜像,启动成功后就可以使用了
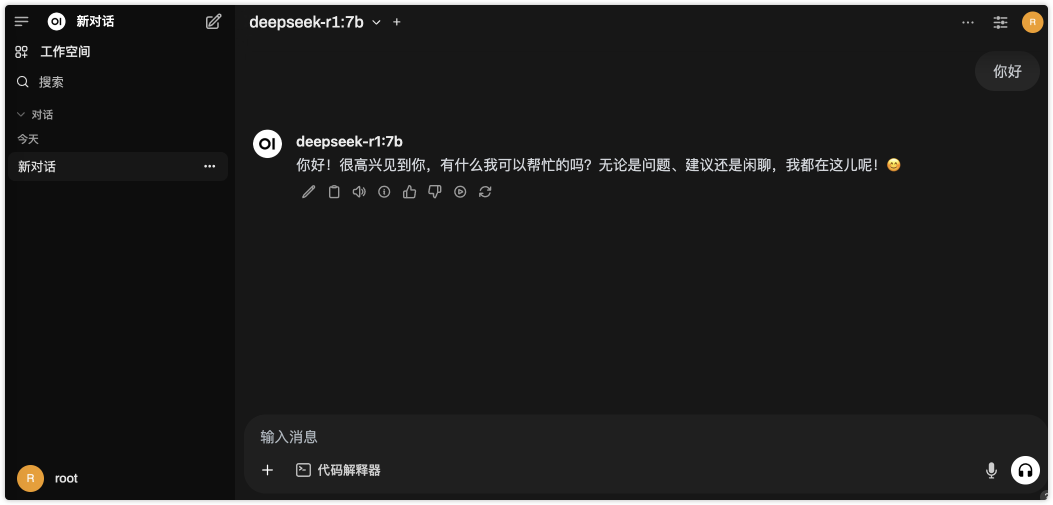
左上角可以选择本地已经下载好的模型

FastGPT
FastGPT 是上一篇文中用到的统一部署大模型的方案,关于它的安装配置这里不再介绍,可参考上篇文章。这里我们直接来配置本地模型
配置模型
首先还是要先使用ollama list列出本地模型,用docker运行FastGPT后打开OneAPI系统
点击创建渠道:
- 将本地的模型写入
- 密钥随便写不影响本地模型使用
- 代理地址一定要使用ip

最后保存后使用编辑器打开config.json配置文件,将在系统中的模型写入配置文件:
{
"llmModels": [
{
"provider": "ollama",
"model": "deepseek-r1:7b",
"name": "deepseek-r1:7b",
// 参考上一篇,省略…
},
{
"provider": "ollama",
"model": "deepseek-r1:14b",
"name": "deepseek-r1:14b",
// 参考上一篇,省略…
},
// …
]
}
修改完后在终端重启容器:
docker compose down
docker compose up -d
创建应用
接下来就可以在FastGPT中创建聊天应用了,步骤和上一篇都是一样的
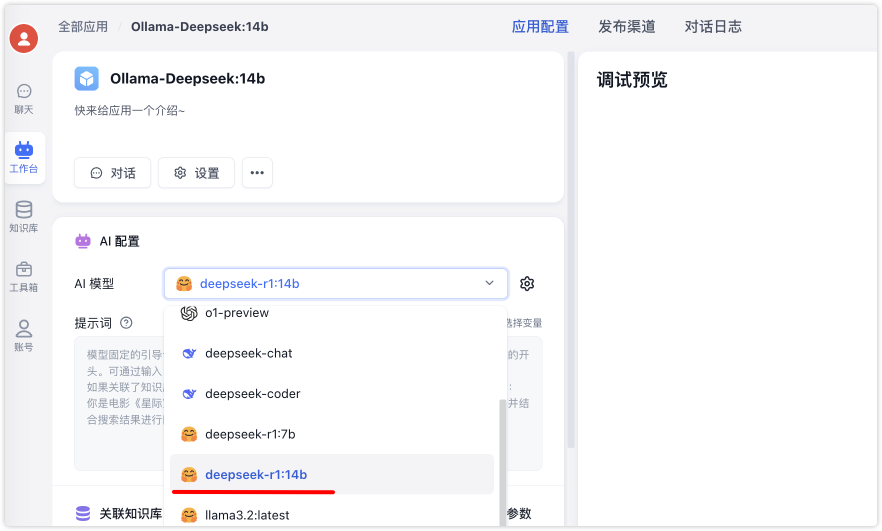
保存发布后来看下效果怎么样❓
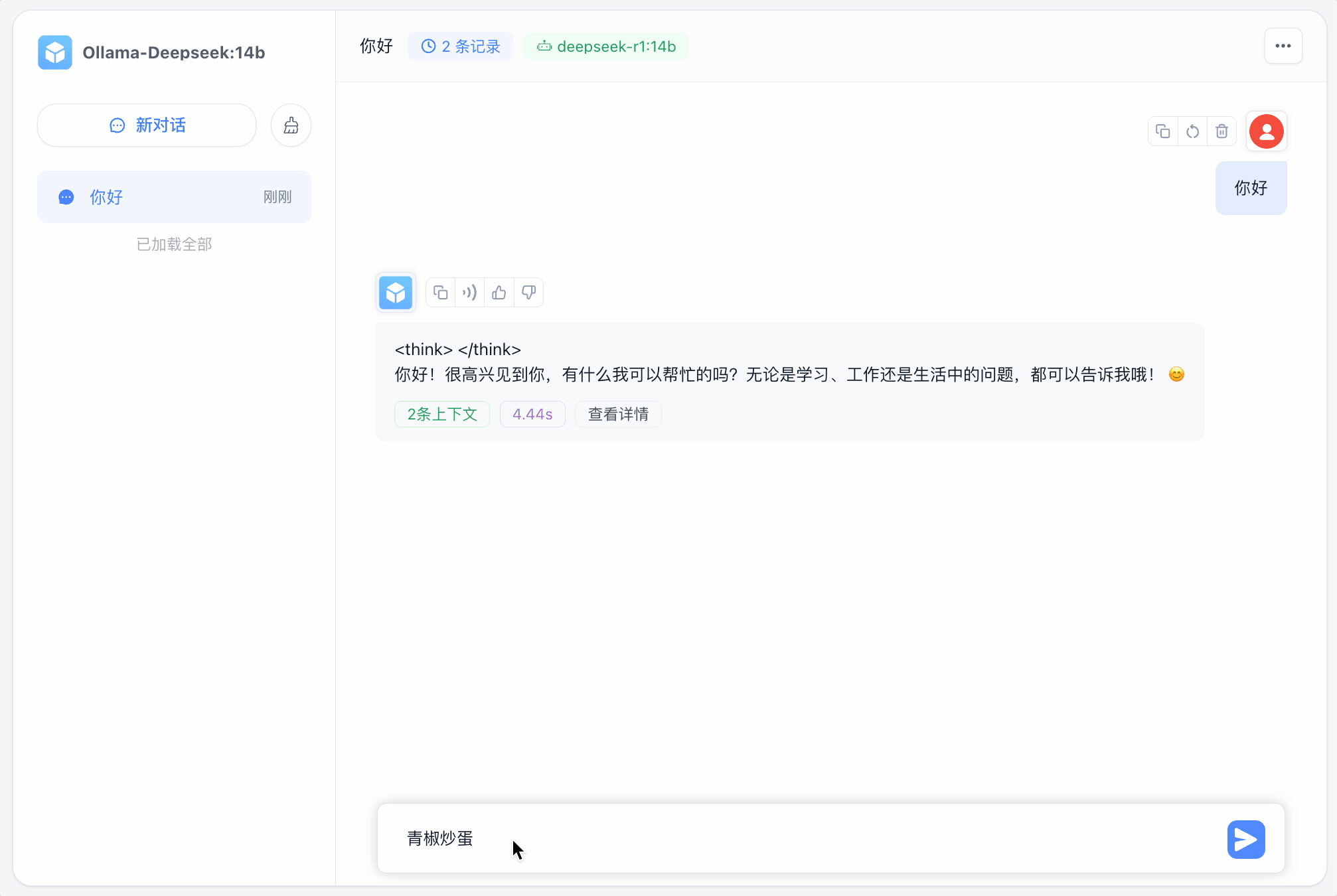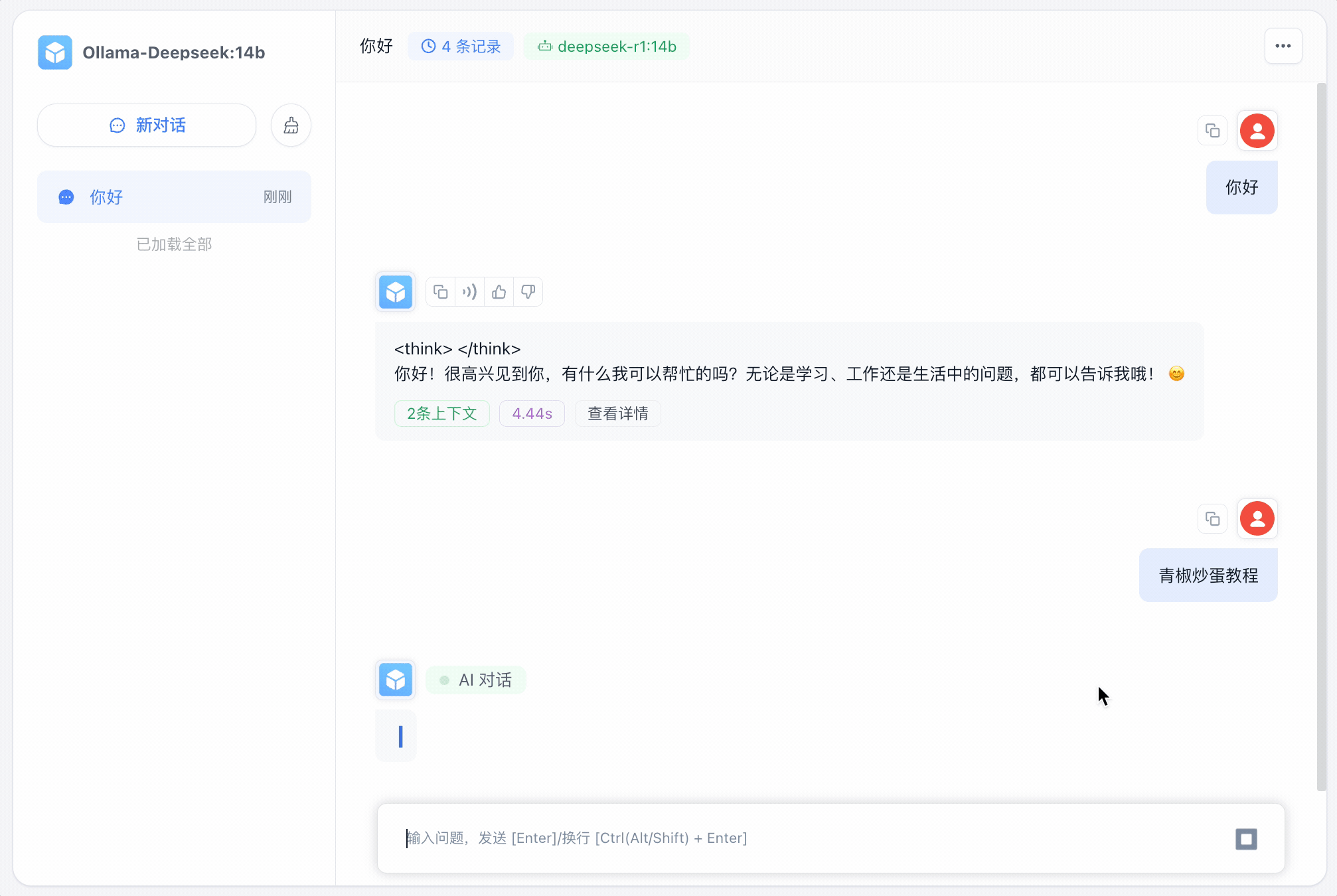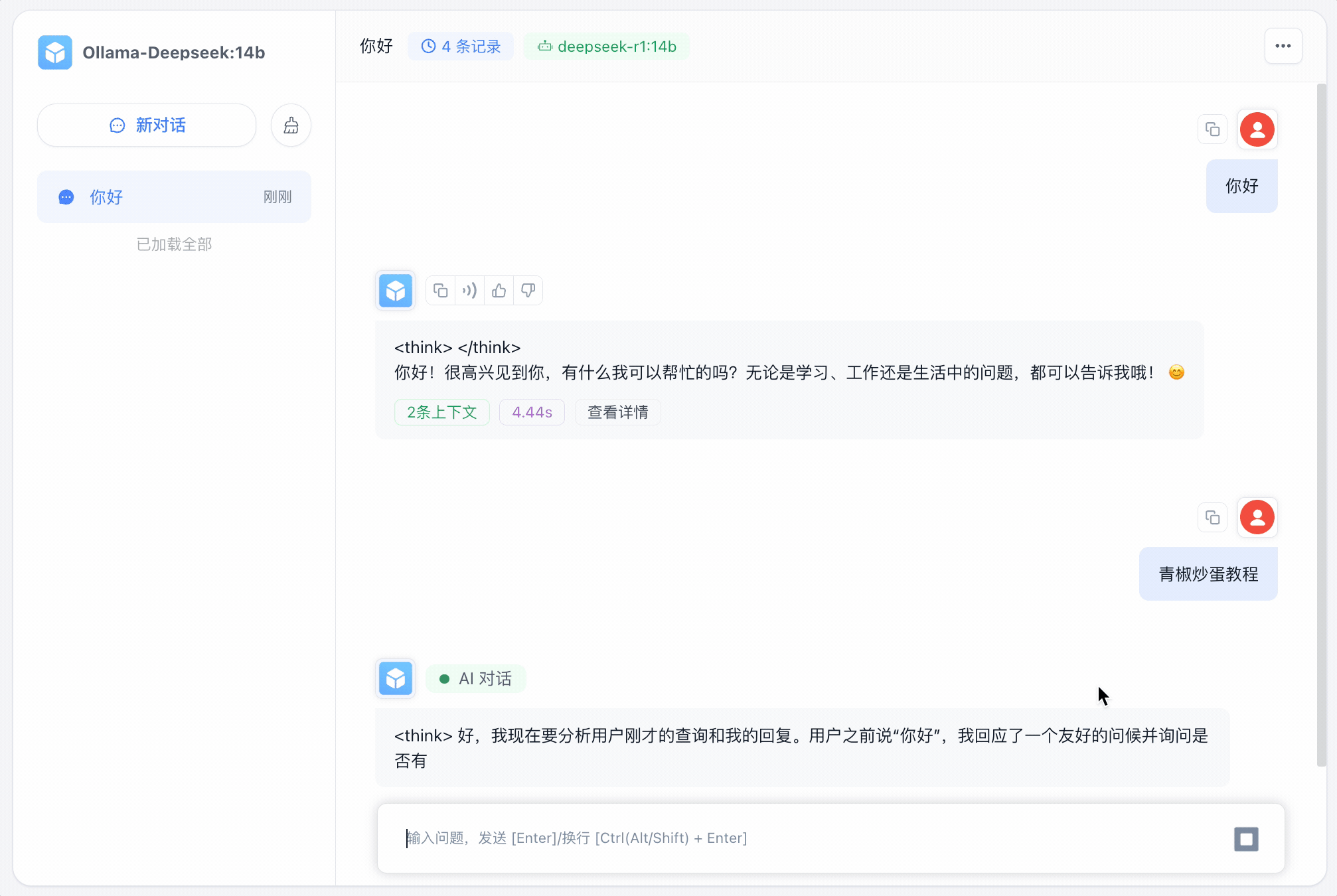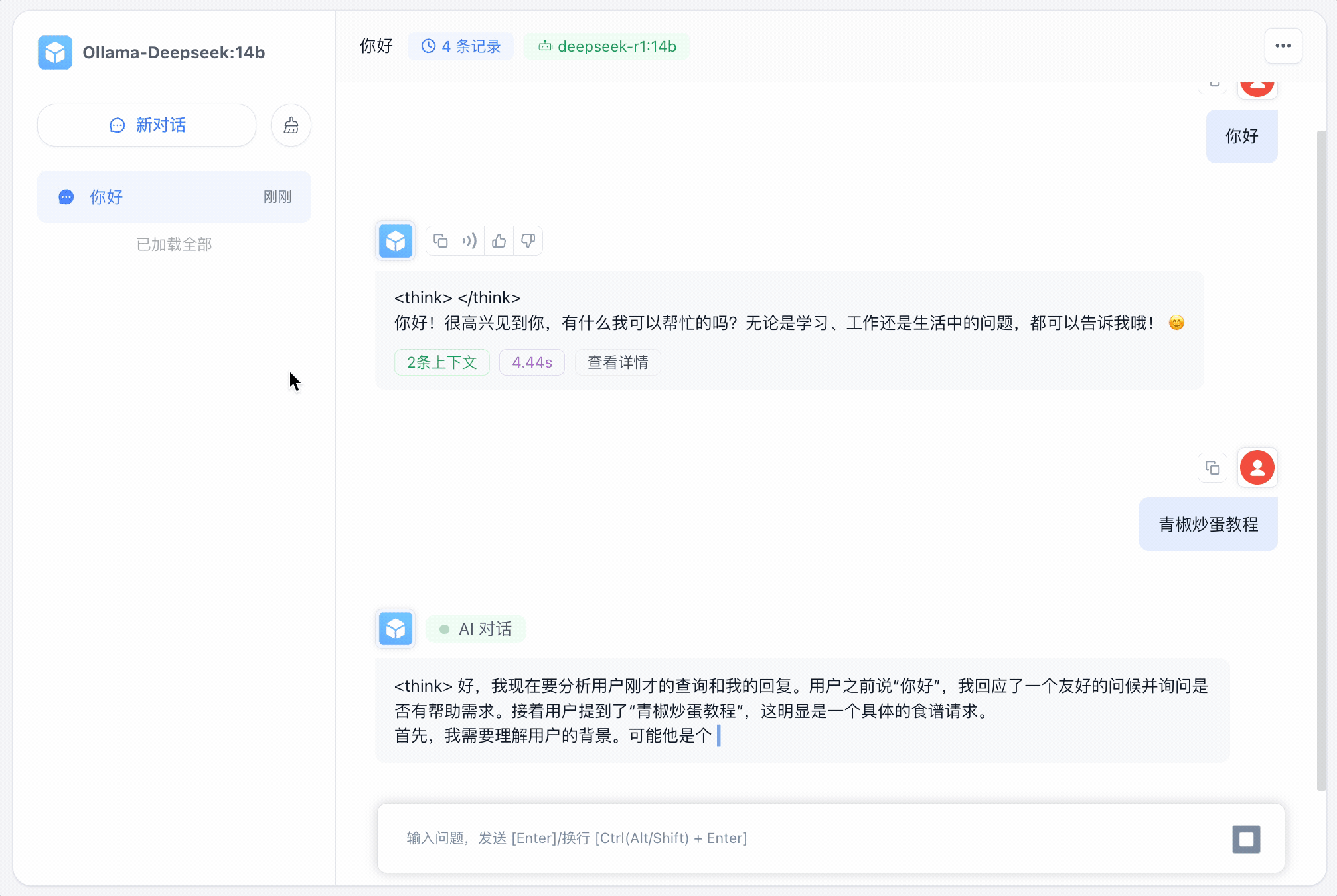
可以看到影响非常迅速‼️ 当然也可以结合知识库,读者可以参考上一篇文章
到这里基本就可以使用了,下面再多介绍几款界面应用
ChatBox
Chatbox AI是一款AI客户端应用和智能助手,支持众多先进的AI模型和API,可在Windows、MacOS、Android、iOS、Linux 和网页版上使用
直接下载桌面应用,下载好后打开设置选择本地模型Ollama API,填写本地ollama地址,就可以选择本地已经下载好的模型了,最后确定即可
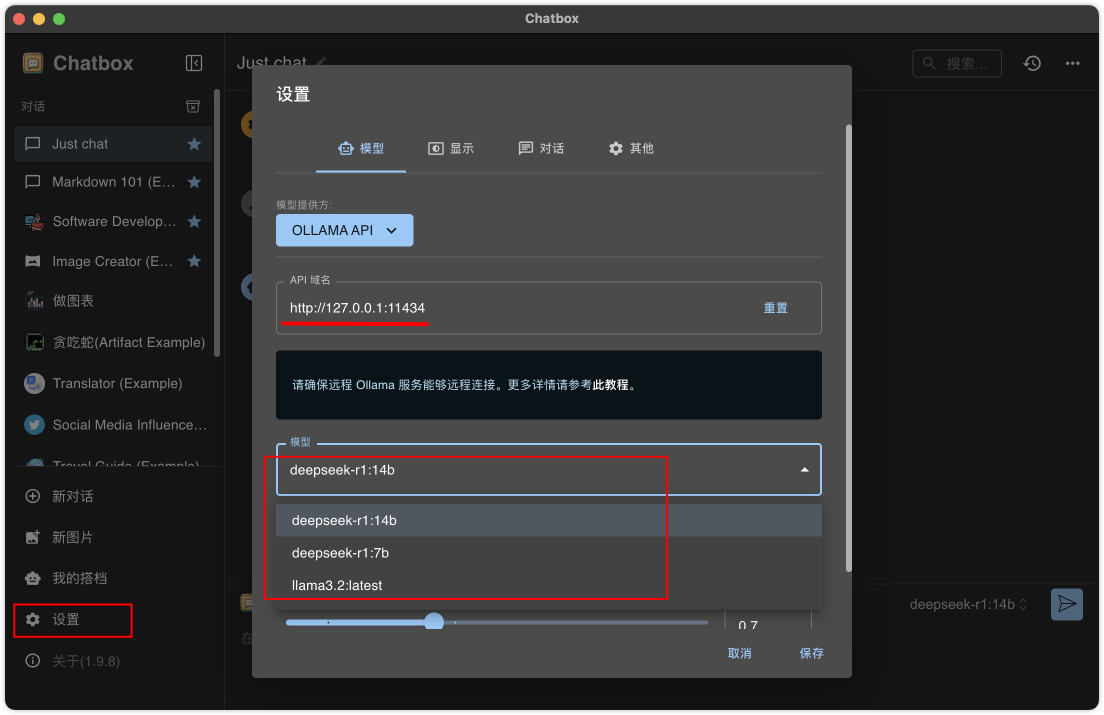
这里是使用llama3.2模型的情况
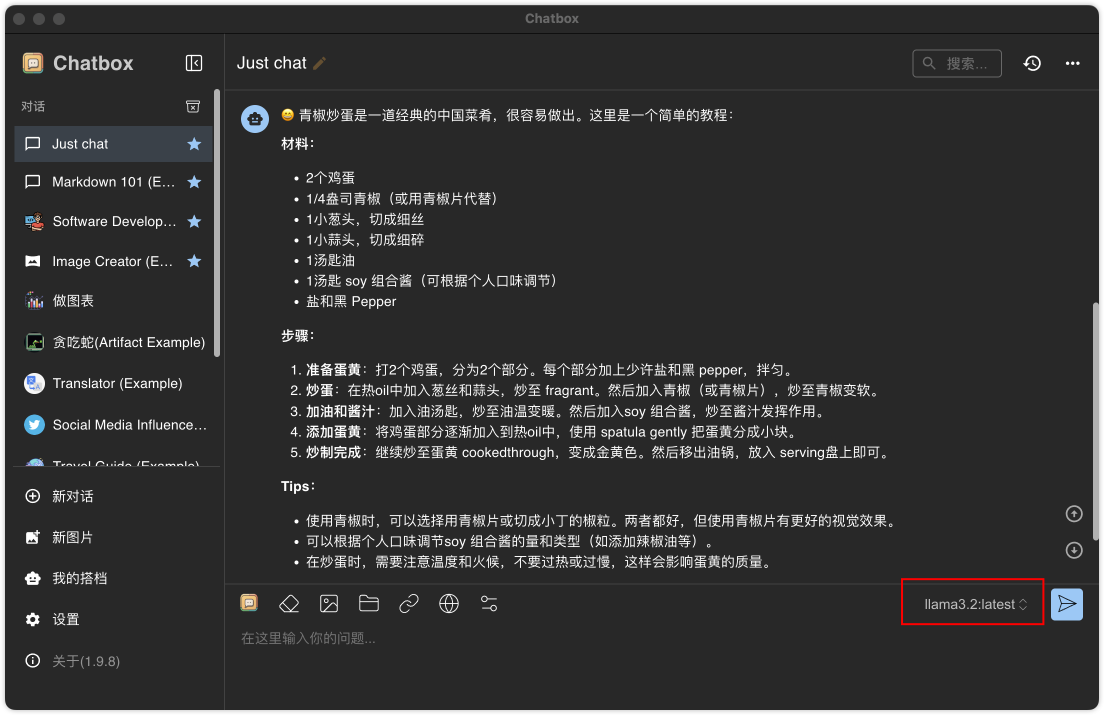
Chatbox比较简单很容易上手,作为日常助手使用完全够用。除此还有很多开源的界面应用、模型部署应用,如:Dify.AI等等,很多都支持知识库、工作流等复杂的情况,感兴趣的读者可以尝试一下
由于图片和格式解析问题,可前往 阅读原文





评论前必须登录!
注册