 网硕互联帮助中心
网硕互联帮助中心上一篇:TingWebServer服务器代码解读02
TingWebServer服务器代码解读02-CSDN博客
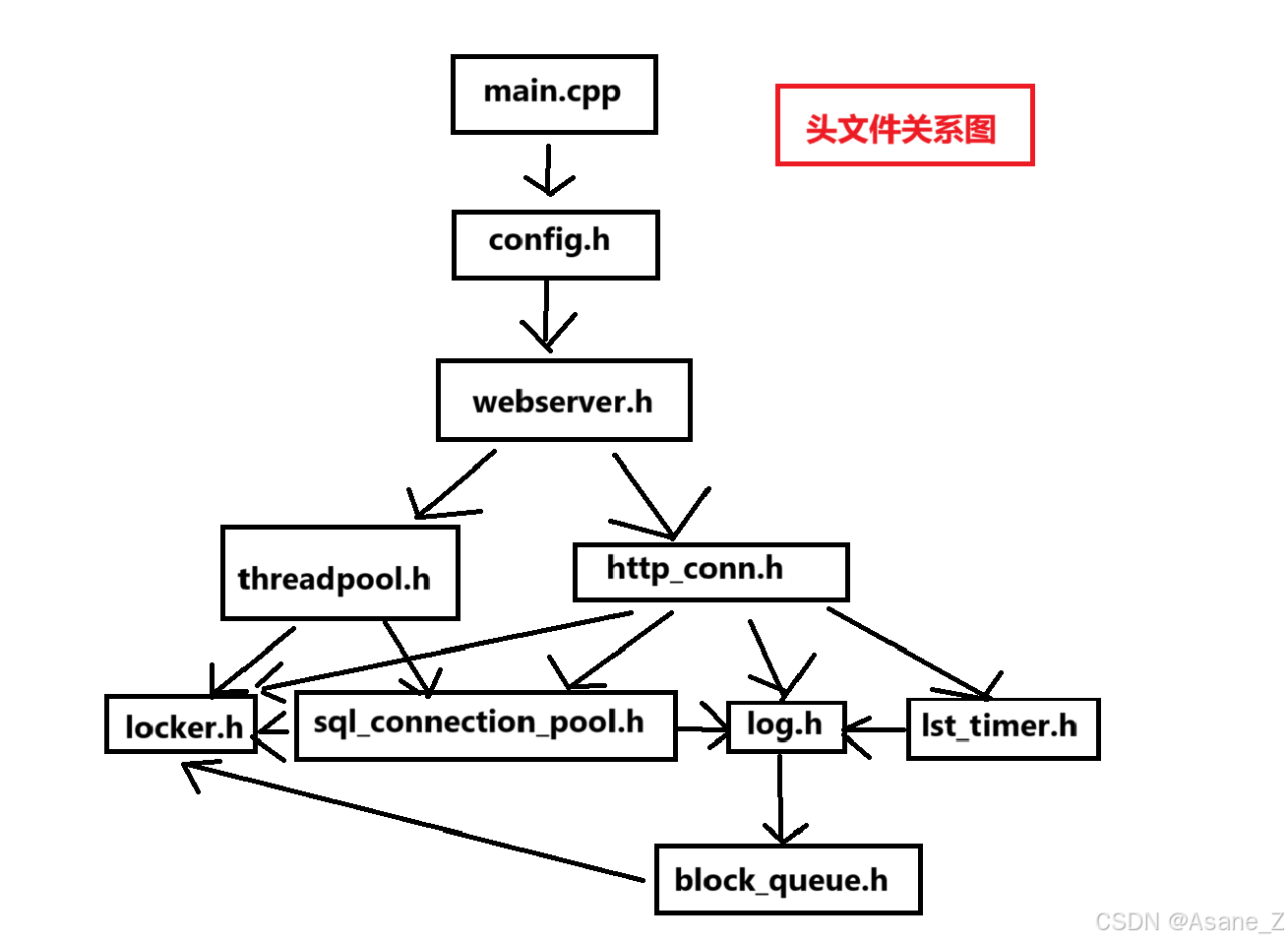
在解读 02中解析完threadpool和http_conn两个文件夹后,我们继续解析后面一行的文件,locker->lst_timer
Locker文件夹
README
线程同步机制包装类
多线程同步,确保任一时刻只能有一个线程能进入关键代码段.
- 信号量
- 互斥锁
- 条件变量
locker.h
一个简单的locker互斥锁的头文件,代码比较简单,所以函数内容也在locker.h中直接给出了,接下来看里面的代码
sem 类(信号量)
class sem
{
public:
sem() {
if (sem_init(&m_sem, 0, 0) != 0) { //信号量初始化为0
throw std::exception();
}
}
sem(int num) {
if (sem_init(&m_sem, 0, num) != 0) { //信号量初始化为输入的num
throw std::exception();
}
}
~sem() { //解析
sem_destroy(&m_sem);
}
bool wait() { //等待信号量,为0即为阻塞
return sem_wait(&m_sem) == 0;
}
bool post() { //增加信号量,为0唤醒一个等待线程
return sem_post(&m_sem) == 0;
}
private:
sem_t m_sem; // 定义一个信号量
};
locker 类(互斥锁)
class locker
{
public:
locker() { //初始化互斥锁,如果失败抛出异常
if (pthread_mutex_init(&m_mutex, NULL) != 0) {
throw std::exception();
}
}
~locker() { //析构
pthread_mutex_destroy(&m_mutex);
}
bool lock() { //锁定互斥锁
return pthread_mutex_lock(&m_mutex) == 0;
}
bool unlock() { //解锁互斥锁
return pthread_mutex_unlock(&m_mutex) == 0;
}
pthread_mutex_t *get() {
return &m_mutex;
}
private:
pthread_mutex_t m_mutex; // 定义互斥锁
};
cond 类(条件变量)
class cond
{
public:
cond() { //初始化条件变量,失败则抛出异常
if (pthread_cond_init(&m_cond, NULL) != 0) {
throw std::exception();
}
}
~cond() { //析构
pthread_cond_destroy(&m_cond);
}
bool wait(pthread_mutex_t *m_mutex) { //等待条件变量的信号
return pthread_cond_wait(&m_cond, m_mutex) == 0;
}
bool timewait(pthread_mutex_t *m_mutex, struct timespec t) { //等待指定时间(超时)后自动返回
return pthread_cond_timedwait(&m_cond, m_mutex, &t) == 0;
}
bool signal() { //发送信号给一个等待的线程
return pthread_cond_signal(&m_cond) == 0;
}
bool broadcast() { //发送信号给所有等待的线程
return pthread_cond_broadcast(&m_cond) == 0;
}
private:
pthread_cond_t m_cond; // 定义条件变量
};
- sem 类实现了信号量的基本功能,允许线程间同步访问。
- locker 类提供了互斥锁的封装,确保多线程环境下对共享资源的独占访问。
- cond 类则实现了条件变量,允许线程根据某个条件同步或协调执行顺序。
CGImysql文件夹
README
校验 & 数据库连接池
数据库连接池
- 单例模式,保证唯一
- list实现连接池
- 连接池为静态大小
- 互斥锁实现线程安全
校验
- HTTP请求采用POST方式
- 登录用户名和密码校验
- 用户注册及多线程注册安全
sql_connection_pool.h
头文件代码
#ifndef _CONNECTION_POOL_
#define _CONNECTION_POOL_
#include <stdio.h>
#include <list>
#include <mysql/mysql.h>
#include <error.h>
#include <string.h>
#include <iostream>
#include <string>
#include "../lock/locker.h"
#include "../log/log.h"
using namespace std;
class connection_pool
{
public:
MYSQL *GetConnection(); //获取数据库连接
bool ReleaseConnection(MYSQL *conn); //释放连接
int GetFreeConn(); //获取连接
void DestroyPool(); //销毁所有连接
//单例模式
static connection_pool *GetInstance();
void init(string url, string User, string PassWord, string DataBaseName, int Port, int MaxConn, int close_log);
private:
connection_pool();
~connection_pool();
int m_MaxConn; //最大连接数
int m_CurConn; //当前已使用的连接数
int m_FreeConn; //当前空闲的连接数
locker lock;
list<MYSQL *> connList; //连接池
sem reserve;
public:
string m_url; //主机地址
string m_Port; //数据库端口号
string m_User; //登陆数据库用户名
string m_PassWord; //登陆数据库密码
string m_DatabaseName; //使用数据库名
int m_close_log;//日志开关
};
class connectionRAII{
public:
connectionRAII(MYSQL **con, connection_pool *connPool);
~connectionRAII();
private:
MYSQL *conRAII;
connection_pool *poolRAII;
};
#endif
sql_connection_pool.cpp
connection_pool 类
connection_pool 是数据库连接池的核心类,负责管理数据库连接的创建、获取、释放和销毁
构造函数:connection_pool
connection_pool::connection_pool()
{
m_CurConn = 0;//当前连接池中正在使用的连接数置0
m_FreeConn = 0;//当前连接池中空闲的连接数置0
}
静态方法:GetInstance
这是一个单例模式的方法,保证只有一个connection_pool实例存在
connection_pool *connection_pool::GetInstance()
{
static connection_pool connPool;
return &connPool;
}
init 方法:
初始化数据库连接池,具体步骤如下:
- 设置数据库连接参数(URL、用户名、密码、数据库名、端口号等)。
- 创建并初始化数据库连接,调用 mysql_real_connect 与数据库建立连接。
- 将每个连接加入connList,并更新空闲连接数m_FreeConn。
void connection_pool::init(string url, string User, string PassWord, string DBName, int Port, int MaxConn, int close_log)
{
m_url = url;
m_Port = Port;
m_User = User;
m_PassWord = PassWord;
m_DatabaseName = DBName;
m_close_log = close_log;
for (int i = 0; i < MaxConn; i++)
{
MYSQL *con = NULL;
con = mysql_init(con);
if (con == NULL)
{
LOG_ERROR("MySQL Error");
exit(1);
}
//调用 mysql_real_connect 与数据库建立连接
con = mysql_real_connect(con, url.c_str(), User.c_str(), PassWord.c_str(), DBName.c_str(), Port, NULL, 0);
if (con == NULL)
{
LOG_ERROR("MySQL Error");
exit(1);
}
connList.push_back(con);//将每个连接加入connList
++m_FreeConn;
}
reserve = sem(m_FreeConn);
m_MaxConn = m_FreeConn;
}
GetConnection 方法:
该方法用于获取一个数据库连接:
- 如果连接池中没有空闲连接,返回NULL。
- 否则,使用信号量reserve.wait()确保当前空闲连接数不会超过最大限制。
- 使用互斥锁lock.lock()来保证线程安全。
- 从连接池中获取一个连接,将其从connList中移除,更新m_FreeConn和m_CurConn。
- 返回可用的数据库连接。
//当有请求时,从数据库连接池中返回一个可用连接,更新使用和空闲连接数
MYSQL *connection_pool::GetConnection()
{
MYSQL *con = NULL;
if (0 == connList.size())//没有空闲连接
return NULL;
reserve.wait();//使用信号量reserve.wait()确保当前空闲连接数不会超过最大限制
lock.lock();//上锁
//获取连接
con = connList.front();
connList.pop_front();
//更新
–m_FreeConn;
++m_CurConn;
lock.unlock();//解锁
return con;//返回可用连接
}
ReleaseConnection 方法:
该方法用于释放一个数据库连接:
- 将连接重新加入connList,更新空闲连接数m_FreeConn和使用中的连接数m_CurConn。
- 使用信号量reserve.post()通知有空闲连接。
//释放当前使用的连接
bool connection_pool::ReleaseConnection(MYSQL *con)
{
if (NULL == con)
return false;
lock.lock();//上锁
//将连接重新加入connList
connList.push_back(con);
//更新空闲连接数m_FreeConn和使用中的连接数m_CurConn
++m_FreeConn;
–m_CurConn;
lock.unlock();//解锁
//使用信号量reserve.post()通知有空闲连接
reserve.post();
return true;
}
DestroyPool 方法:
销毁连接池,关闭所有数据库连接,并清空connList。
//销毁数据库连接池
void connection_pool::DestroyPool()
{
lock.lock();//上锁
if (connList.size() > 0)
{
list<MYSQL *>::iterator it;//迭代器循环
for (it = connList.begin(); it != connList.end(); ++it)
{
MYSQL *con = *it;
mysql_close(con);//关闭连接
}
//清零
m_CurConn = 0;
m_FreeConn = 0;
connList.clear();
}
lock.unlock();//解锁
}
GetFreeConn 方法:
返回当前空闲的数据库连接数
//当前空闲的连接数
int connection_pool::GetFreeConn()
{
return this->m_FreeConn;
}
析构函数:
connection_pool::~connection_pool()
{
DestroyPool();//在销毁connection_pool对象时,调用DestroyPool销毁连接池
}
connectionRAII 类
onnectionRAII 类是一个RAII(Resource Acquisition Is Initialization)管理类,用于自动管理数据库连接的获取与释放。
构造函数:connectionRAII
构造函数通过connPool->GetConnection()获取一个数据库连接,并将其赋给SQL指针。conRAII和poolRAII成员变量保存当前连接和连接池的引用,确保在connectionRAII对象销毁时,自动释放连接
connectionRAII::connectionRAII(MYSQL **SQL, connection_pool *connPool)
{
*SQL = connPool->GetConnection();
conRAII = *SQL;
poolRAII = connPool;
}
析构函数:
析构函数在对象销毁时,调用connPool->ReleaseConnection(conRAII)释放数据库连接
connectionRAII::~connectionRAII()
{
poolRAII->ReleaseConnection(conRAII);
}
log文件夹
README
同步/异步日志系统
同步/异步日志系统主要涉及了两个模块,一个是日志模块,一个是阻塞队列模块,其中加入阻塞队列模块主要是解决异步写入日志做准备.
- 自定义阻塞队列
- 单例模式创建日志
- 同步日志
- 异步日志
- 实现按天、超行分类
log.h
//头文件部分
#ifndef LOG_H
#define LOG_H
#include <stdio.h>
#include <iostream>
#include <string>
#include <stdarg.h>
#include <pthread.h>
#include "block_queue.h"
//log类定义
class Log
{
public:
// C++11以后,使用局部变量懒汉不用加锁
static Log *get_instance()
{
static Log instance; // 局部静态变量实例化(懒汉式单例模式)
return &instance;
}
static void *flush_log_thread(void *args)
{
Log::get_instance()->async_write_log(); // 调用 Log 类的异步日志写入函数
}
//init() 方法
bool init(const char *file_name, int close_log, int log_buf_size = 8192, int split_lines = 5000000, int max_queue_size = 0);
//write_log() 方法
void write_log(int level, const char *format, …);
//flush() 方法
void flush(void);
private:
Log();
virtual ~Log();
void *async_write_log()
{
string single_log;
//从阻塞队列中取出一个日志string,写入文件
while (m_log_queue->pop(single_log))
{
m_mutex.lock();
fputs(single_log.c_str(), m_fp);
m_mutex.unlock();
}
}
private:
char dir_name[128]; //路径名
char log_name[128]; //log文件名
int m_split_lines; //日志最大行数
int m_log_buf_size; //日志缓冲区大小
long long m_count; //日志行数记录
int m_today; //因为按天分类,记录当前时间是那一天
FILE *m_fp; //打开log的文件指针
char *m_buf;
block_queue<string> *m_log_queue; //阻塞队列
bool m_is_async; //是否同步标志位
locker m_mutex;
int m_close_log; //关闭日志
};
//宏定义部分
#define LOG_DEBUG(format, …) if(0 == m_close_log) {Log::get_instance()->write_log(0, format, ##__VA_ARGS__); Log::get_instance()->flush();}
#define LOG_INFO(format, …) if(0 == m_close_log) {Log::get_instance()->write_log(1, format, ##__VA_ARGS__); Log::get_instance()->flush();}
#define LOG_WARN(format, …) if(0 == m_close_log) {Log::get_instance()->write_log(2, format, ##__VA_ARGS__); Log::get_instance()->flush();}
#define LOG_ERROR(format, …) if(0 == m_close_log) {Log::get_instance()->write_log(3, format, ##__VA_ARGS__); Log::get_instance()->flush();}
#endif
log.cpp
- 同步与异步模式:日志系统支持两种模式。异步模式通过创建线程和使用阻塞队列将日志写入文件,减少了阻塞操作,提高了性能。同步模式则是直接在日志函数中写入文件。
- 按天或按行分割日志:日志会根据时间或者行数进行切割。每天生成新的日志文件,或者当日志行数达到指定上限时创建新的日志文件。
- 线程安全:通过 m_mutex 互斥锁保护共享资源,确保多线程环境下日志写入不会发生冲突
类成员变量及构造函数:log
Log::Log()
{
m_count = 0;//初始化日志行数计数器
m_is_async = false;//默认为同步模式,不启用异步日志记录
}
析构函数 :~Log()
Log::~Log()
{
if (m_fp != NULL)
{
fclose(m_fp); // 如果文件指针 `m_fp` 不为 NULL,关闭文件
}
}
初始化函数:init()
init():用于初始化日志系统,包括设置日志文件名、路径、日志缓冲区大小、分割行数等。
- 如果 max_queue_size >= 1,则启用异步日志记录并创建一个新的线程来执行日志写入。
- 根据传入的文件名和当前时间,生成日志文件的完整路径和文件名。
- 打开日志文件并准备写入。
bool Log::init(const char *file_name, int close_log, int log_buf_size, int split_lines, int max_queue_size)
{
// 如果设置了max_queue_size, 则设置为异步
if (max_queue_size >= 1)
{
m_is_async = true; // 启用异步日志写入
m_log_queue = new block_queue<string>(max_queue_size); // 创建一个阻塞队列用于存放日志
pthread_t tid;
// 创建一个线程来执行日志的异步写入
pthread_create(&tid, NULL, flush_log_thread, NULL);
}
m_close_log = close_log; // 设置日志是否关闭的标志
m_log_buf_size = log_buf_size; // 设置日志缓冲区大小
m_buf = new char[m_log_buf_size]; // 创建日志缓冲区
memset(m_buf, '\\0', m_log_buf_size); // 初始化缓冲区为 0
m_split_lines = split_lines; // 设置日志文件的最大行数
// 获取当前系统时间
time_t t = time(NULL);
struct tm *sys_tm = localtime(&t);
struct tm my_tm = *sys_tm;
const char *p = strrchr(file_name, '/');
char log_full_name[256] = {0};
if (p == NULL)
{
snprintf(log_full_name, 255, "%d_%02d_%02d_%s", my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday, file_name);
}
else
{
strcpy(log_name, p + 1); // 复制文件名
strncpy(dir_name, file_name, p – file_name + 1); // 复制路径名
snprintf(log_full_name, 255, "%s%d_%02d_%02d_%s", dir_name, my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday, log_name);
}
m_today = my_tm.tm_mday; // 设置当前日期
m_fp = fopen(log_full_name, "a"); // 打开日志文件(以追加模式)
if (m_fp == NULL)
{
return false; // 如果文件打开失败,返回 false
}
return true;
}
日志写入函数 :write_log()
write_log():这是日志记录的核心方法,它首先格式化日志信息并确定日志级别(如 debug、info、warn、error)。然后判断是否需要切换日志文件(按天或按行分割),并在需要时创建新文件。最后,日志信息会根据是否启用异步模式,写入到文件或者阻塞队列中。
void Log::write_log(int level, const char *format, …)
{
struct timeval now = {0, 0};
gettimeofday(&now, NULL); // 获取当前时间(秒和微秒)
time_t t = now.tv_sec;
struct tm *sys_tm = localtime(&t); // 转换为本地时间
struct tm my_tm = *sys_tm;
char s[16] = {0};
switch (level)
{
case 0: strcpy(s, "[debug]:"); break;
case 1: strcpy(s, "[info]:"); break;
case 2: strcpy(s, "[warn]:"); break;
case 3: strcpy(s, "[erro]:"); break;
default: strcpy(s, "[info]:"); break;
}
m_mutex.lock(); // 锁住日志系统,防止多个线程同时写日志
m_count++; // 增加日志行数计数器
// 如果当前日期与日志文件日期不一致,或者日志行数达到最大行数,切换日志文件
if (m_today != my_tm.tm_mday || m_count % m_split_lines == 0)
{
char new_log[256] = {0};
fflush(m_fp); // 刷新文件缓冲区
fclose(m_fp); // 关闭当前日志文件
char tail[16] = {0};
snprintf(tail, 16, "%d_%02d_%02d_", my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday);
// 如果日期发生变化,切换到新的日志文件
if (m_today != my_tm.tm_mday)
{
snprintf(new_log, 255, "%s%s%s", dir_name, tail, log_name);
m_today = my_tm.tm_mday;
m_count = 0; // 重置日志行数
}
else
{
snprintf(new_log, 255, "%s%s%s.%lld", dir_name, tail, log_name, m_count / m_split_lines);
}
m_fp = fopen(new_log, "a"); // 重新打开日志文件
}
m_mutex.unlock(); // 解锁日志系统
va_list valst;
va_start(valst, format); // 开始处理可变参数
string log_str;
m_mutex.lock();
// 写入日志的具体时间
int n = snprintf(m_buf, 48, "%d-%02d-%02d %02d:%02d:%02d.%06ld %s ",
my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday,
my_tm.tm_hour, my_tm.tm_min, my_tm.tm_sec, now.tv_usec, s);
// 写入格式化的日志信息
int m = vsnprintf(m_buf + n, m_log_buf_size – n – 1, format, valst);
m_buf[n + m] = '\\n'; // 添加换行符
m_buf[n + m + 1] = '\\0';
log_str = m_buf; // 将日志内容存入字符串
m_mutex.unlock(); // 解锁
// 如果是异步模式,日志写入队列;否则直接写入文件
if (m_is_async && !m_log_queue->full())
{
m_log_queue->push(log_str); // 将日志推入阻塞队列
}
else
{
m_mutex.lock();
fputs(log_str.c_str(), m_fp); // 写入日志文件
m_mutex.unlock();
}
va_end(valst); // 结束可变参数处理
}
刷新日志文件函数:flush()
void Log::flush(void)
{
m_mutex.lock();
fflush(m_fp); // 强制刷新文件流缓冲区
m_mutex.unlock();
}
block_quene.h
block_queue 类是一个基于循环数组实现的阻塞队列,具有线程安全的特性,支持同步和超时等待的 pop 操作。它在生产者-消费者模式中非常常见,主要用于多线程日志系统等场景
block_queue类
初始化block_queue
初始化一个最大容量为 max_size 的队列,默认值是 1000
block_queue(int max_size = 1000)
{
if (max_size <= 0)//判断大小
{
exit(-1);
}
m_max_size = max_size;
m_array = new T[max_size];
m_size = 0;
m_front = -1;
m_back = -1;
}
清空队列函数:clear
void clear()
{
m_mutex.lock();
m_size = 0;
m_front = -1;
m_back = -1;
m_mutex.unlock();
}
析构函数
释放动态分配的数组 m_array 资源
~block_queue()
{
m_mutex.lock();
if (m_array != NULL)
delete [] m_array;
m_mutex.unlock();
}
判断队列是否满:full
bool full()
{
m_mutex.lock();
if (m_size >= m_max_size)//判断条件
{
m_mutex.unlock();
return true;
}
m_mutex.unlock();
return false;
}
判断队列是否为空:empty
bool empty()
{
m_mutex.lock();
if (0 == m_size)
{
m_mutex.unlock();
return true;
}
m_mutex.unlock();
return false;
}
返回队首元素:front
bool front(T &value)
{
m_mutex.lock();
if (0 == m_size)
{
m_mutex.unlock();
return false;
}
value = m_array[m_front];
m_mutex.unlock();
return true;
}
返回队尾元素:back
bool back(T &value)
{
m_mutex.lock();
if (0 == m_size)
{
m_mutex.unlock();
return false;
}
value = m_array[m_back];
m_mutex.unlock();
return true;
}
求队列长度:size
int size()
{
int tmp = 0;
m_mutex.lock();
tmp = m_size;
m_mutex.unlock();
return tmp;
}
求最大长度:max_size
int max_size()
{
int tmp = 0;
m_mutex.lock();
tmp = m_max_size;
m_mutex.unlock();
return tmp;
}
以上都是一些很简单的函数,实现语句就一两句话,主要还是为了模块化运行考虑,把简单功能封装
入队 (push)
- 先检查是否队列满了,满了就返回 false。
- 计算 m_back 的新位置 (m_back + 1) % m_max_size,实现循环数组结构。
- 存入数据,增加 m_size。
- 通过 m_cond.broadcast() 唤醒所有可能等待 pop 的线程
bool push(const T &item)
{
m_mutex.lock();
if (m_size >= m_max_size)//检查队列长度
{
m_cond.broadcast();
m_mutex.unlock();
return false;
}
m_back = (m_back + 1) % m_max_size;//计算新位置
m_array[m_back] = item;
m_size++;
m_cond.broadcast();//唤醒线程
m_mutex.unlock();
return true;
}
出队 (pop)
- 如果队列为空,则调用 m_cond.wait(m_mutex.get()),阻塞等待生产者放入新元素。
- 取出 m_front + 1 位置的元素,并更新 m_front,实现循环数组结构。
- m_size–,释放队列空间。
bool pop(T &item)
{
m_mutex.lock();
while (m_size <= 0)
{
if (!m_cond.wait(m_mutex.get()))
{
m_mutex.unlock();
return false;
}
}
m_front = (m_front + 1) % m_max_size;
item = m_array[m_front];
m_size–;
m_mutex.unlock();
return true;
}
超时出队 (pop with timeout)
- 如果队列为空,先计算超时时间 t(基于 gettimeofday())。
- 调用 m_cond.timewait(m_mutex.get(), t),如果超时仍然为空,返回 false。
- 否则执行正常的 pop 逻辑。
bool pop(T &item, int ms_timeout)
{
struct timespec t = {0, 0};
struct timeval now = {0, 0};
gettimeofday(&now, NULL);
m_mutex.lock();
if (m_size <= 0)
{
t.tv_sec = now.tv_sec + ms_timeout / 1000;
t.tv_nsec = (ms_timeout % 1000) * 1000;
if (!m_cond.timewait(m_mutex.get(), t))
{
m_mutex.unlock();
return false;
}
}
if (m_size <= 0)
{
m_mutex.unlock();
return false;
}
m_front = (m_front + 1) % m_max_size;
item = m_array[m_front];
m_size–;
m_mutex.unlock();
return true;
}
Timer文件夹
README
定时器处理非活动连接
由于非活跃连接占用了连接资源,严重影响服务器的性能,通过实现一个服务器定时器,处理这种非活跃连接,释放连接资源。利用alarm函数周期性地触发SIGALRM信号,该信号的信号处理函数利用管道通知主循环执行定时器链表上的定时任务.
- 统一事件源
- 基于升序链表的定时器
- 处理非活动连接
lst_timer.h
头文件定义,没有多少内容,详情看接下来的lst_timer.cpp文件
#ifndef LST_TIMER
#define LST_TIMER
#include <unistd.h>
#include <signal.h>
#include <sys/types.h>
#include <sys/epoll.h>
#include <fcntl.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <assert.h>
#include <sys/stat.h>
#include <string.h>
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <stdarg.h>
#include <errno.h>
#include <sys/wait.h>
#include <sys/uio.h>
#include <time.h>
#include "../log/log.h"
class util_timer;
struct client_data
{
sockaddr_in address;
int sockfd;
util_timer *timer;
};
class util_timer
{
public:
util_timer() : prev(NULL), next(NULL) {}
public:
time_t expire;
void (* cb_func)(client_data *);
client_data *user_data;
util_timer *prev;
util_timer *next;
};
class sort_timer_lst
{
public:
sort_timer_lst();
~sort_timer_lst();
void add_timer(util_timer *timer);
void adjust_timer(util_timer *timer);
void del_timer(util_timer *timer);
void tick();
private:
void add_timer(util_timer *timer, util_timer *lst_head);
util_timer *head;
util_timer *tail;
};
class Utils
{
public:
Utils() {}
~Utils() {}
void init(int timeslot);
//对文件描述符设置非阻塞
int setnonblocking(int fd);
//将内核事件表注册读事件,ET模式,选择开启EPOLLONESHOT
void addfd(int epollfd, int fd, bool one_shot, int TRIGMode);
//信号处理函数
static void sig_handler(int sig);
//设置信号函数
void addsig(int sig, void(handler)(int), bool restart = true);
//定时处理任务,重新定时以不断触发SIGALRM信号
void timer_handler();
void show_error(int connfd, const char *info);
public:
static int *u_pipefd;
sort_timer_lst m_timer_lst;
static int u_epollfd;
int m_TIMESLOT;
};
void cb_func(client_data *user_data);
#endif
lst_timer.cpp
构造函数
sort_timer_lst::sort_timer_lst()//把队列头尾清零
{
head = NULL;
tail = NULL;
}
析构函数
循环释放队列
sort_timer_lst::~sort_timer_lst()
{
util_timer *tmp = head;
while (tmp)
{
head = tmp->next;
delete tmp;
tmp = head;
}
}
添加计时器:add_timer
/ 向定时器链表添加定时器
void sort_timer_lst::add_timer(util_timer *timer)
{
if (!timer) // 如果定时器为空,直接返回
{
return;
}
if (!head) // 如果链表为空,将定时器设为头尾
{
head = tail = timer;
return;
}
// 如果新定时器的过期时间小于当前头节点的过期时间
if (timer->expire < head->expire)
{
timer->next = head; // 新定时器成为新的头节点
head->prev = timer; // 旧头节点的前指针指向新定时器
head = timer; // 更新头指针
return;
}
add_timer(timer, head); // 否则,将定时器插入到合适的位置
}
调整定时器的位置:adjust_timer
// 调整定时器的位置
void sort_timer_lst::adjust_timer(util_timer *timer)
{
if (!timer) // 如果定时器为空,返回
{
return;
}
util_timer *tmp = timer->next; // 获取下一个定时器
// 如果定时器本身已经在正确的位置,返回
if (!tmp || (timer->expire < tmp->expire))
{
return;
}
// 如果是头定时器,移动头指针并重新插入
if (timer == head)
{
head = head->next; // 移动头指针
head->prev = NULL; // 更新头指针的前指针
timer->next = NULL; // 将定时器的下一个指针置为空
add_timer(timer, head); // 重新插入
}
else // 否则,链表中间或尾部的定时器
{
timer->prev->next = timer->next; // 断开当前定时器
timer->next->prev = timer->prev; // 从链表中移除
add_timer(timer, timer->next); // 重新插入
}
}
定时器检测函数:tick
遍历列表检测计时器是否过期,调用回调函数,删除已过期计时器
// 定时器检测,处理到期的定时器
void sort_timer_lst::tick()
{
if (!head) // 如果链表为空,返回
{
return;
}
time_t cur = time(NULL); // 获取当前时间
util_timer *tmp = head; // 从头节点开始检查
while (tmp) // 遍历链表
{
if (cur < tmp->expire) // 如果当前时间还未到期
{
break; // 不再检查后面的定时器
}
tmp->cb_func(tmp->user_data); // 执行回调函数
head = tmp->next; // 更新头指针
if (head) // 如果头指针不为空
{
head->prev = NULL; // 更新头节点的前指针
}
delete tmp; // 删除已到期的定时器
tmp = head; // 继续遍历
}
}
向已排序的链表中插入定时器函数:add_timer
遍历列表寻找合适位置,插入位置,更新列表
// 向已排序的链表中插入定时器
void sort_timer_lst::add_timer(util_timer *timer, util_timer *lst_head)
{
util_timer *prev = lst_head; // 记录前一个节点
util_timer *tmp = prev->next; // 记录当前节点
// 遍历寻找合适的插入位置
while (tmp)
{
if (timer->expire < tmp->expire) // 如果新定时器过期时间更早
{
prev->next = timer; // 插入新定时器
timer->next = tmp; // 更新新定时器的下一个指针
tmp->prev = timer; // 更新当前节点的前指针
timer->prev = prev; // 更新前一个节点的后指针
break; // 退出循环
}
prev = tmp; // 更新前一个节点
tmp = tmp->next; // 更新当前节点
}
// 如果没有找到合适的位置,插入到尾部
if (!tmp)
{
prev->next = timer; // 更新前一个节点的下一个指针
timer->prev = prev; // 维持双向链接
timer->next = NULL; // 更新新定时器的下一个指针
tail = timer; // 更新尾指针
}
}
Utils 类的定义与实现
定义函数:init
void Utils::init(int timeslot)
{
m_TIMESLOT = timeslot; // 初始化时间槽
}
设置文件描述符为非阻塞函数: setnonblocking
// 设置文件描述符为非阻塞
int Utils::setnonblocking(int fd)
{
int old_option = fcntl(fd, F_GETFL); // 获取当前文件描述符的选项
int new_option = old_option | O_NONBLOCK; // 设置非阻塞标志
fcntl(fd, F_SETFL, new_option); // 应用新的标志
return old_option; // 返回原来的选项
}
向内核事件表注册读事件函数:addfd
// 向内核事件表注册读事件,ET模式,选择开启EPOLLONESHOT
void Utils::addfd(int epollfd, int fd, bool one_shot, int TRIGMode)
{
epoll_event event;
event.data.fd = fd; // 设置事件数据为文件描述符
// 根据触发模式选择事件类型
if (1 == TRIGMode)
event.events = EPOLLIN | EPOLLET | EPOLLRDHUP; // 边缘触发
else
event.events = EPOLLIN | EPOLLRDHUP; // 水平触发
if (one_shot) // 如果启用单次触发
event.events |= EPOLLONESHOT; // 设置单次触发标志
epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event); // 注册事件
setnonblocking(fd); // 设置文件描述符为非阻塞
}
信号处理函数:sig_handler
// 信号处理函数
void Utils::sig_handler(int sig)
{
// 为保证函数可重入,保留原来的 errno
int save_errno = errno;
int msg = sig;
send(u_pipefd[1], (char *)&msg, 1, 0); // 发送信号信息到管道
errno = save_errno; // 还原 errno
}
设置信号函数:addsig
// 设置信号函数
void Utils::addsig(int sig, void(handler)(int), bool restart)
{
struct sigaction sa;
memset(&sa, '\\0', sizeof(sa)); // 清零信号集
sa.sa_handler = handler; // 设置处理函数
if (restart)
sa.sa_flags |= SA_RESTART; // 设置重启标志
sigfillset(&sa.sa_mask); // 填充信号集
assert(sigaction(sig, &sa, NULL) != -1); // 注册信号处理函数
}
定时处理任务函数:timer_handler
// 定时处理任务,触发 SIGALRM 信号
void Utils::timer_handler()
{
m_timer_lst.tick(); // 处理定时器
alarm(m_TIMESLOT); // 重新设定定时器
}
发送错误信息并关闭连接函数:show_error
// 发送错误信息并关闭连接
void Utils::show_error(int connfd, const char *info)
{
send(connfd, info, strlen(info), 0); // 发送错误信息
close(connfd); // 关闭连接
}
客户端数据的回调函数 :cb_func
// 静态成员变量的初始化
int *Utils::u_pipefd = 0; // 用于处理信号的管道
int Utils::u_epollfd = 0; // epoll 文件描述符
// 客户端数据的回调函数
void cb_func(client_data *user_data)
{
epoll_ctl(Utils::u_epollfd, EPOLL_CTL_DEL, user_data->sockfd, 0); // 从事件表中删除文件描述符
assert(user_data); // 确保用户数据存在
close(user_data->sockfd); // 关闭套接字
http_conn::m_user_count–; // 减少活动用户计数
}
总结:
至此,TingWebServer的所有代码都留出了注释和函数解释,下一篇将会从服务器开始运行到发送请求到最后的服务器关闭,带着所有函数名过一遍具体的服务器运行流程


评论前必须登录!
注册