 网硕互联帮助中心
网硕互联帮助中心国产昇腾AI服务器上的大模型算力需求解析
随着人工智能技术的迅猛发展,特别是大型语言模型(LLM)的兴起,对于高效计算资源的需求日益增长。本文将探讨在国产昇腾AI服务器上训练和推理大模型时所需的算力资源,并通过具体例子来说明如何评估这些需求。
训练资源需求
昇腾AI服务器作为国产高性能计算平台,在处理大规模模型时表现出色。根据昇腾社区提供的资料,不同的大模型对于算力的要求各有差异。例如,LLaMA2-70B 模型在 4K tokens 长度下进行预训练时,需要至少四台配备八张 64GB NPU 卡的服务器才能完成任务。
为了更直观地理解服务器所能支持的模型规模,我们可以采用一个简化的估算公式来计算所需的 GPU/NPU 内存容量: 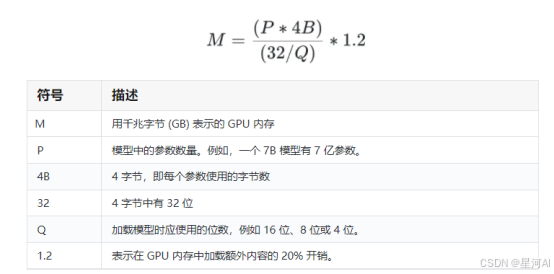
M
=
(
参数量
×
参数位宽
)
(
内存带宽
/
模型位数
)
×
系数
M = \\frac{(参数量 \\times 参数位宽)}{(内存带宽 / 模型位数)} \\times 系数
M=(内存带宽/模型位数)(参数量×参数位宽)×系数
假设我们要运行 16 位精度的 Llama2 70B 模型,则计算如下:
M
=
(
70
×
4
)
(
32
/
16
)
×
1.2
≈
168
G
B
M = \\frac{(70 \\times 4)}{(32 / 16)} \\times 1.2 \\approx 168GB
M=(32/16)(70×4)×1.2≈168GB
同样,如果使用 4 位量化版本的 Llama2 70B 模型,其所需的 GPU 内存容量则降低至:
M
=
(
70
×
4
)
(
32
/
4
)
×
1.2
≈
42
G
B
M = \\frac{(70 \\times 4)}{(32 / 4)} \\times 1.2 \\approx 42GB
M=(32/4)(70×4)×1.2≈42GB
值得注意的是,LoRA(Low-Rank Adaptation)作为一种轻量级的微调技术,其核心理念在于只更新预训练模型中的少量额外参数,而不会改变原有模型的参数。这意味着与全模型训练相比,LoRA 训练在计算资源上的消耗要少得多。然而,尽管 LoRA 仅对少量参数进行更新,它依然需要将整个基础模型加载至显存中。因此,LoRA 训练对显存的需求实际上与基础模型的大小相当。如果基础模型本身较大,那么即使采用 LoRA 进行微调,仍需要较大的显存支持。
此外,在实际应用中,当输入文本长度较长时,LoRA 训练过程中显存使用量也会相应增加。这是因为较长的输入序列会导致模型在前向传播和反向传播过程中需要存储更多的中间变量,从而增加了显存负担。例如,一个基础模型占用 10GB 显存的情况下,若输入文本长度较长,则可能需要超过 10GB 的显存来处理这些额外的数据负载。因此,在选择训练设备时,不仅要考虑基础模型的大小,还需要根据输入数据的长度来评估显存需求。
在单机训练的基础上,若要提升训练效率或处理更大的数据集和更长的文本序列,则可以通过部署多台服务器实现分布式训练。分布式训练不仅有助于加快模型训练的速度,还能通过并行利用多台服务器上的计算资源来满足大规模模型训练的需求,特别是当单个设备的内存不足以处理长文本模型时,分布式训练成为一种必要的解决方案。
推理资源需求
在推理阶段,昇腾AI服务器同样表现优异。根据不同的量化方式,单台服务器可以支持不同规模的模型进行推理:(注:该部分数据来自华为供应商)
- 对于 INT4 量化版本的 LLaMA2 模型,单台服务器可以支持高达 220B 参数量的模型。
- 对于 INT8 量化版本的 LLaMA2 模型,单台服务器可以支持 175B 参数量的模型。
- 对于 FP16 或 BF16 版本的 LLaMA2 或 LLaMA3 模型,单台服务器则可以支持 70B 参数量的模型。
结论
通过对昇腾AI服务器上大模型训练和推理资源需求的分析,我们可以发现,合理的硬件配置结合高效的量化技术,能够显著提高计算效率并降低成本。开发者可以根据具体的应用场景选择合适的模型量化方式和硬件配置,以实现最佳性能。
参考资料
- 昇腾社区模型链接
- 昇腾社区大模型工具ModelLink
- 大模型算力需求分析
通过上述资料和公式计算,我们可以更好地规划和利用昇腾AI服务器的计算资源,以应对日益复杂的人工智能应用挑战。
参考图片
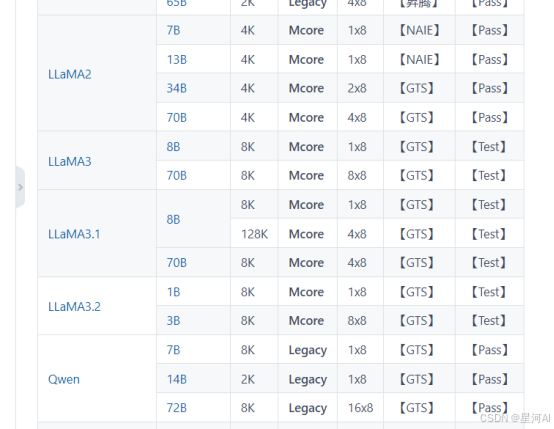
昇腾社区模型链接页面截图,PASS表示已经测试的模型,Test还在测试:





评论前必须登录!
注册