 网硕互联帮助中心
网硕互联帮助中心《弹性裸金属服务器》系列,共包含以下文章:
- 弹性裸金属服务器和神龙虚拟化(一):功能特点
- 弹性裸金属服务器和神龙虚拟化(二):适用场景
- 弹性裸金属服务器和神龙虚拟化(三):弹性裸金属技术
😊 如果您觉得这篇文章有用 ✔️ 的话,请给博主一个一键三连 🚀🚀🚀 吧 (点赞 🧡、关注 💛、收藏 💚)!!!您的支持 💖💖💖 将激励 🔥 博主输出更多优质内容!!!
弹性裸金属服务器和神龙虚拟化(三):弹性裸金属技术
- 1.传统 KVM 虚拟化系统的问题
-
- 1.1 CPU 计算特性损失
- 1.2 资源争抢不可避免
- 1.3 I/O 性能瓶颈
- 2.弹性裸金属技术实现
-
- 2.1 VPC 和 EBS 云盘接入
- 2.2 实现大量弹性网卡(ENI)和 EBS 云盘设备接入
- 3.X-Dragon Hypervisor 基于神龙的软硬一体的虚拟化技术
-
- 3.1 自研虚拟 CPU 调度器 —— VOS
- 3.2 内存优化:内存分配器 VMEM 与用户态 QEMU 内存瘦身
- 3.3 虚拟化运行加速
- 3.4 极速启动
- 3.5 物理机 CPU 全供给虚拟机
1.传统 KVM 虚拟化系统的问题
2003 年,Xen 在 SOSP 发表 Xen and the Art of Virtualization,拉开了 x86 平台虚拟化技术的大幕。2006 年,AWS 发布 EC2(Elastic Compute Cloud),同年发布 S3(Simple Storage Service),拉开了公共云服务的大幕。EC2 的核心正是基于 Xen 虚拟化技术。虚拟化技术赋予了 EC2 核心产品价值 —— 弹性,同时虚拟化技术给网络虚拟化、存储虚拟化,和管控系统提供了业务部署点。
🚀 SOSP(Symposium on Operating Systems Principles,操作系统原理研讨会):操作系统(OS)领域有两个国际顶尖会议:SOSP 和 OSDI,SOSP 只在奇数年召开,OSDI 只在偶数年召开。
第一代虚拟化技术的特征是:Xen / KVM + 软件 network vSwitch + 软件 storage initiator + 管控等 All on Xeon。这代技术的痛点和思考,如下图所示。
🚀 软件网络 vSwitch(虚拟交换机)是一种在虚拟化环境中运行的软件交换机,用于连接虚拟机(VM)和物理网络设备。它模拟物理交换机的功能,允许虚拟机之间以及虚拟机与外部网络之间的通信。 🚀 软件存储 Initiator(存储启动器)是一种在主机或虚拟机上运行的软件,用于发起与存储设备(如 SAN 或 NAS)的通信。它通过特定的存储协议(如 iSCSI、Fibre Channel 等)与存储目标(Target)进行交互,使主机能够访问远程存储资源。

1.1 CPU 计算特性损失
众所周知,IaaS 公共云技术的核心是 Intel 至强处理器 VT 等 硬件辅助虚拟化技术(Hardware-assisted virtualization),配合主流虚拟化系统软件(KVM / Xen / VMware ESXi 等),实现了 IaaS 弹性计算;客户则是通过 ECS(或者 AWS EC2)购买虚拟机(VM)形式的计算资源。
得益于高度成熟的虚拟化技术,VM 形式的计算资源 “几乎” 等价于客户线下的物理服务器资源,但是 “几乎” 并不是 “完全”。一个典型的案例就是 Intel 至强处理器的 VT 硬件辅助虚拟化能力会被公共云服务提供商的虚拟化系统 “消费掉”,客户无法在公共云 VM 实例中再次部署虚拟化系统,致使传统 OpenStack 和 VMware based workload 无法在公共云部署。
客户希望用一套 OpenStack / VMware 统一管理 公共云线上资源 和 专有云线下资源,同时在控制面和数据面打通线上线下资源,在兼顾专有云数据安全、法律合规的基础上,充分利用公共云计算资源的弹性能力,但是由于 Intel 至强处理器 VT 硬件辅助虚拟化能力 “被消费”,使得此种 混合云技术 很难在公共云实现。云原生安全容器创新依赖 Intel VT 硬件辅助虚拟化能力输出,这是传统虚拟化无法解决的问题。
1.2 资源争抢不可避免
以传统的 KVM 虚拟化系统为例,双路 Skylake(96 个 HT)计算资源的虚拟化典型部署情况是:有 8 个 HT 部署网络虚拟化 vSwitch 和存储虚拟化,对外售卖 88 个 HT 作为 vCPU 计算资源。我们需要注意到,对外售卖的 88 HT vCPU 计算资源和 8 HT 网络 / 存储虚拟化是部署在同一组 Skylake CPU 上的,那么如下共享资源争抢是不可避免的。
- CPU DDR 带宽、LLC 等共享资源的争抢。在机头网络带宽迅速提升的当下,DDR 带宽、LLC 等资源争抢现象愈发突出。
- 半虚拟化(Para-virtualized)I/O 设备模型等资源争抢引入售卖 CPU 抖动和售卖 I/O 抖动。
- 存储和网络等 I/O 内部层级化 HQoS 难于实施。一般而言,层级化 HQoS 是解决资源争抢的有效手段,电信级网络设备一般会部署 HQoS 进行资源调度,而 HQoS 的典型部署方法需要通过芯片实现。
🚀 HT 指的是 Hyper-Threading Technology(超线程技术),这是英特尔(Intel)开发的一种技术,旨在提高 CPU 的并行处理能力。 🚀 层级化 HQoS(Hierarchical Quality of Service,分层服务质量) 是一种高级的网络流量管理技术,用于在复杂网络环境中对不同层次的流量进行精细化的优先级控制和资源分配。它通过多层级的调度和策略管理,确保关键业务流量的服务质量(QoS),同时优化网络资源的利用率。
1.3 I/O 性能瓶颈
传统 KVM 虚拟化系统由(计算虚拟化)QEMU-KVM + (网络虚拟化)DPDK based vSwitch + (存储虚拟化)SPDK based I/O initiator 构成。
🚀 QEMU 是一个开源的硬件虚拟化工具,主要用于模拟计算机硬件环境,支持多种架构(如 x86、ARM、PowerPC 等)。它可以单独使用,也可以与 KVM(Kernel-based Virtual Machine)结合,提供高效的虚拟化解决方案。 🚀 DPDK(Data Plane Development Kit)是一个开源的用户态网络数据平面开发工具包,旨在加速数据包处理性能。它通过绕过操作系统内核,直接在用户态处理网络数据包,显著提高了网络应用的性能。 🚀 SPDK(Storage Performance Development Kit)是一个开源的用户态存储性能开发工具包,专注于加速存储应用的性能。它通过将存储 I/O 操作转移到用户态,减少内核开销,从而提升存储性能。
在 Intel 引入 VT 硬件虚拟化支持后,配合 KVM、Xen 等虚拟化系统软件,由 CPU 指令处理的数据面和 KVM 等虚拟化系统软件形成了控制面及异常处理路径,此种软硬件协同设计既实现了 CPU 和内存虚拟化的数据路径的最小开销,又保留了 KVM 控制路径和异常处理路径的高度灵活性。
同处于数据路径的存储虚拟化和网络虚拟化虽然通过 DPDK 和 SPDK 等技术接近了软件优化的技术极限,但是仍然无法和芯片的加速性能媲美。特别是在网络吞吐向 100GbE 演进的过程中,交换网络的带宽能力和 Intel 至强处理器的处理能力间的差距逐渐拉大,在传统 KVM 虚拟化系统下,通过 DPDK、SPDK 等纯软件进行 I/O 性能优化的瓶颈日渐凸显。
2.弹性裸金属技术实现
第一代虚拟化技术的业务痛点,催生了第二代虚拟化技术的产生,弹性裸金属产品也应运而生。那么第二代虚拟化技术具备哪些特征呢?
- 1️⃣ 全部 I/O 设备通过 VT-d 设备直通模式进入 VM,以此减少 para-virtualization I/O 半虚拟化开销。
- 2️⃣ 随着 VT-d 设备直通的引入,网络虚拟化和存储虚拟化需要一个新的业务部署点。
- 3️⃣ VT-d 设备直通引入后,SR-IOV 等技术却无法达到和传统 QEMU PV 设备一样的灵活性,I/O 硬件虚拟化催生 Intel scalable IOV 的业务诉求。
- 4️⃣ 随着存储虚拟化和网络虚拟化新的业务部署点的产生,这个业务部署点很显然需要针对计算、网络、存储、安全等 IaaS 核心业务部署定制化芯片加速。
- 5️⃣ 同时支持传统 VM、弹性裸金属服务器、安全容器等 IaaS 最新业务诉求。
🚀 SR-IOV(Single Root I/O Virtualization,单根 I/O 虚拟化) 是一种硬件虚拟化技术,允许单个物理设备(如网卡或存储控制器)被虚拟化为多个虚拟设备,并直接分配给多个虚拟机(VM)使用。SR-IOV 通过硬件级别的虚拟化,显著提升了虚拟机的 I/O 性能,同时减少了 Hypervisor(虚拟化管理程序)的干预。 🚀 Intel Scalable IOV(Scalable I/O Virtualization,可扩展 I/O 虚拟化) 是 Intel 提出的一种新一代 I/O 虚拟化技术,旨在解决传统 SR-IOV 在可扩展性和灵活性方面的局限性。Scalable IOV 通过更细粒度的资源分配和管理,支持更大规模的虚拟化环境,同时优化性能和资源利用率。
简而言之,Hypervisor 的主要组件全部下沉进入一个定制计算节点,该定制计算节点完成 I/O 设备虚拟化、网络虚拟化、存储虚拟化和管控部署,以及安全特性部署等。
而主机侧,针对公共云的需求,从计算和内存原来的 QUME + KVM 方式,经过高度定制和瘦身后,降低了主机资源占用并提升计算服务质量,演化到了裸金属架构。
第二代虚拟化技术使弹性裸金属的产品落地成为可能。阿里云在 2017 年 10 月举行的杭州云栖大会上正式发布弹性裸金属产品,同年 11 月,AWS reinvent 发布 EC 2 版本弹性裸金属产品。中美公共云服务提供商可以说在弹性裸金属的产品定义、产品适用场景和技术上殊途同归。弹性裸金属的核心产品技术逻辑:通过技术创新,使普通物理服务器具备虚拟机的弹性和使用体验。
正是有了这个逻辑,我们可以推演出技术创新的突破点:通过软硬一体化的技术手段,让普通物理服务器能够无缝接入云平台的管控系统、VPC 云网络和 EBS 云盘。
2.1 VPC 和 EBS 云盘接入
我们知道在虚拟化技术中,虚拟机是通过 Virtio 实现网络和存储 I/O 设备的;同时,我们注意到,Virtio 这个半虚拟化设备模型实际上是严格按照 “真实” PCIe 设备规范的定义而实现的 I/O 设备。也就是说,Virtio 半虚拟化设备完全可以通过芯片实现。
🚀 Virtio 是一种用于虚拟化环境的 I/O 设备标准化框架,旨在提高虚拟机(VM)与主机之间网络、存储和其他 I/O 设备的性能。Virtio 通过提供一组通用的虚拟设备接口,简化了虚拟机的 I/O 操作,并减少了 Hypervisor(虚拟化管理程序)的干预,从而提升了虚拟机的 I/O 性能。 🚀 PCIe 的全称是 Peripheral Component Interconnect Express,中文通常称为 高速外围组件互联 或 PCI 高速总线。它是计算机中用于连接高速外围设备(如显卡、网卡、存储控制器等)的总线标准。
在通过芯片实现 Virtio 的时候,考虑到 VPC 和 EBS 云盘实现的复杂度,我们采用了新的模式:让芯片透传 PCIe TLP 包到可编程处理器,然后通过可编程处理器复用 QEMU 已有的成熟的 Virtio 后端代码。此种模式能够最大限度地保持既有的虚拟化架构,做到云平台管控系统、VPC 系统、EBS 云盘系统的 “零修改”。
- 芯片透传 PCIe TLP 包:
- 硬件芯片(如网卡或存储控制器)可以直接将 PCIe TLP 数据包传递给一个可编程处理器(如 FPGA 或智能网卡)。
- 这样,硬件设备的数据可以直接被虚拟机访问,而不需要经过 Hypervisor 的软件模拟层。
- 通过可编程处理器复用 Virtio 后端代码:
- 可编程处理器(如 FPGA 或智能网卡)可以运行 Virtio 的后端代码。
- Virtio 后端代码是 Hypervisor 中已经成熟的代码,用于处理虚拟机的 I/O 请求。
- 通过复用这些代码,虚拟机可以直接使用 Virtio 接口与硬件通信,而不需要修改现有的 Virtio 实现。
- 保持既有虚拟化架构:
- 这种方式不需要对现有的虚拟化架构(如 QEMU、KVM)进行修改。
- 虚拟机仍然通过 Virtio 接口与硬件通信,Hypervisor 仍然负责管理虚拟机。
- “零修改”:
- 云平台的管控系统、VPC(虚拟私有云)系统、EBS(云盘)系统都不需要修改。
- 这意味着现有的云平台可以无缝支持这种新的硬件加速方式。
2.2 实现大量弹性网卡(ENI)和 EBS 云盘设备接入
VT-x / KVM 虚拟化技术具有天然技术优势,支持大量网络和存储设备。而弹性裸金属产品的核心出发点就是要兼具虚拟机和传统物理机的优点。虚拟机对大量网络设备和存储设备的支持,必须在弹性裸金属产品中予以实现。
在多种规格的网卡和存储 PCIe I/O 设备接入时,根据 PCIe 规范有两个方法:
- 1️⃣ 通过多级 PCIe switch 扩展,实现大量 PCIe switch downstream port,然后每个 PCIe switch downstream port 挂载一个 PCIe I/O 设备;
- 2️⃣ 通过 PCIe SR-IOV 技术,支持大量 PCIe virtual function(VF)设备。
🚀 PCIe Switch Downstream Port 是指 PCIe 交换机(PCIe Switch)上 连接下游设备 的端口。 🚀 PCIe Virtual Function(VF,虚拟功能) 是 SR-IOV 技术中的一个核心概念。它允许将一个物理 PCIe 设备(如网卡或存储控制器)虚拟化为多个独立的虚拟设备,每个虚拟设备可以直接分配给一个虚拟机(VM)使用,从而实现硬件资源的高效共享和性能优化。
进一步对比虚拟机 I/O 设备,我们可以看到 设备的热插拔、Guest OS 的零侵入 是公共云 IaaS 产品的刚需。只有通过多级 PCIe switch 扩展模式,才能通过 PCIe native hotplug 技术标准,实现上述和虚拟机一致的设备热插拔和 Guest OS 零侵入。
🚀 PCIe Native Hotplug 是指 PCIe 设备在不关闭系统电源的情况下,能够被安全地插入或移除 的功能。这种功能允许用户或管理员在系统运行时动态添加或移除 PCIe 设备(如显卡、网卡、NVMe SSD 等),而无需重启系统。
产品需求明确后,我们创新性地通过芯片 RTL 实现了全球第一个片上多级 PCIe switch 扩展,当前最多能够支持 63 个设备,以此实现大数量规格的网络 ENI 和存储 EBS 云盘 PCIe I/O 设备接入;同时由于支持原生 PCIe 原生热插拔能力,保证了 Guest OS 的零侵入,以及客户在 Open API 和控制台等方面和虚拟机一致的使用体验。
3.X-Dragon Hypervisor 基于神龙的软硬一体的虚拟化技术
在阿里云神龙硬件平台下,虚拟化架构也做了相应的升级,使计算虚拟化部分的架构更加清晰简捷,让虚拟机能提供接近物理机的性能。如下图所示,神龙虚拟化架构的主要特点是:
- 1️⃣ I/O 链路从传统的通过软件实现转变为通过硬件和直通设备实现;
- 2️⃣ 存储虚拟化、网络虚拟化都在 MOC 卡上实现;
- 3️⃣ 同时将管控系统、监控程序等都下沉到 MOC 卡上。
- 4️⃣ 在提供计算服务的物理机上,只运行自己裁剪的 Linux 操作系统和轻量化的虚拟机监控器。
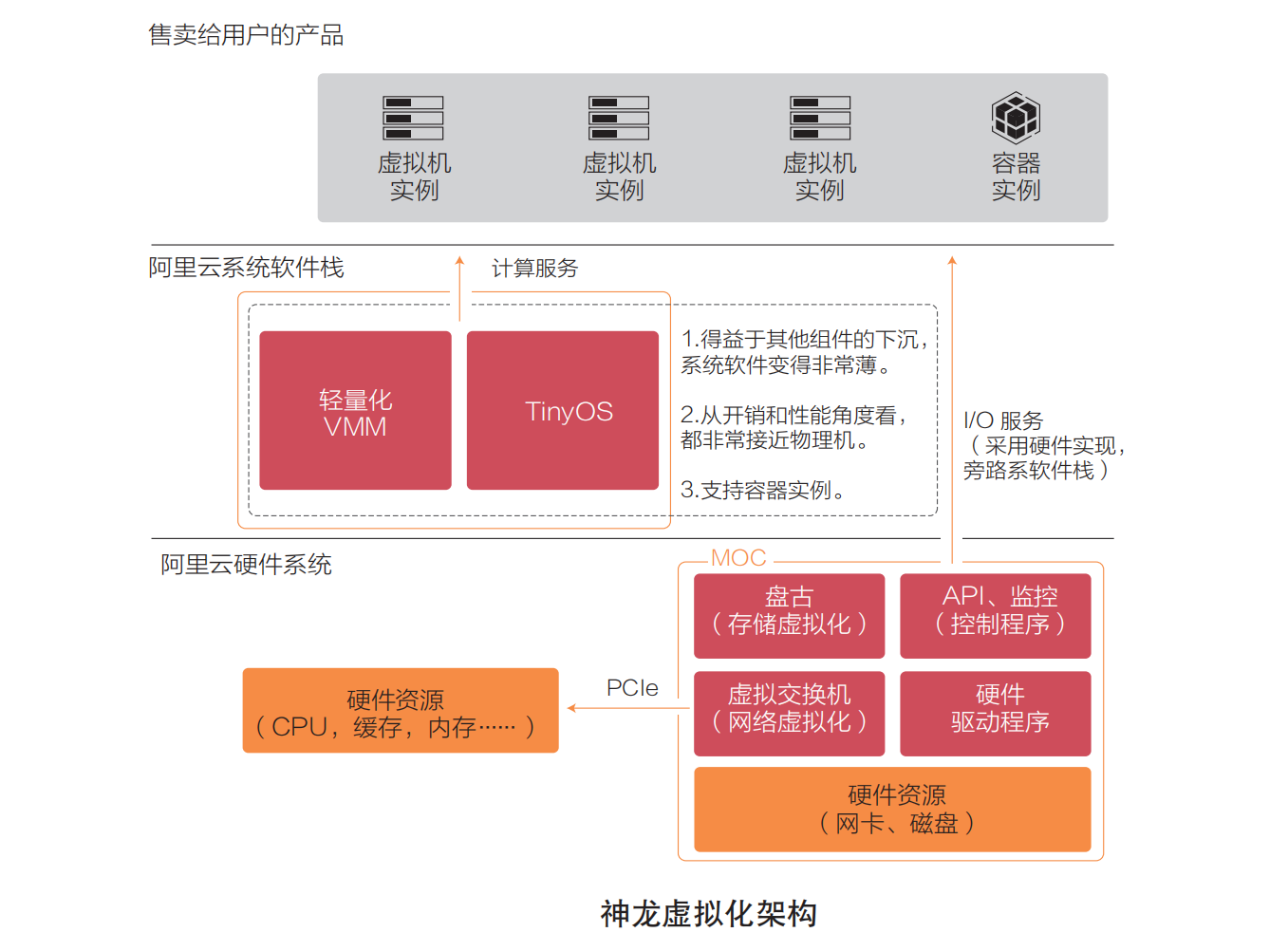 神龙虚拟化架构比起传统的 KVM 虚拟化的关键优化技术点简要描述如下。
神龙虚拟化架构比起传统的 KVM 虚拟化的关键优化技术点简要描述如下。
3.1 自研虚拟 CPU 调度器 —— VOS
VOS(VM-Oriented Scheduler)是面向虚拟机的调度器,是阿里云在神龙平台上自研的调度器,减少了虚拟 CPU 调度开销,同时将其他控制面的作业调度给虚拟 CPU 带来的争抢下降一个数量级研发的更加稳定和高效的计算虚拟化产品。如下图所示,VOS 调度器实现的是非公平调度(与内核中的 CFS 调度器不同),让虚拟 CPU 线程具有更高执行优先级,保证客户购买的虚拟机的计算性能,而控制面的作业调度执行被安排在预先设定的一个较低优先级和预设时间片中投机执行,而且控制面的作业是可以被内核态抢占的。 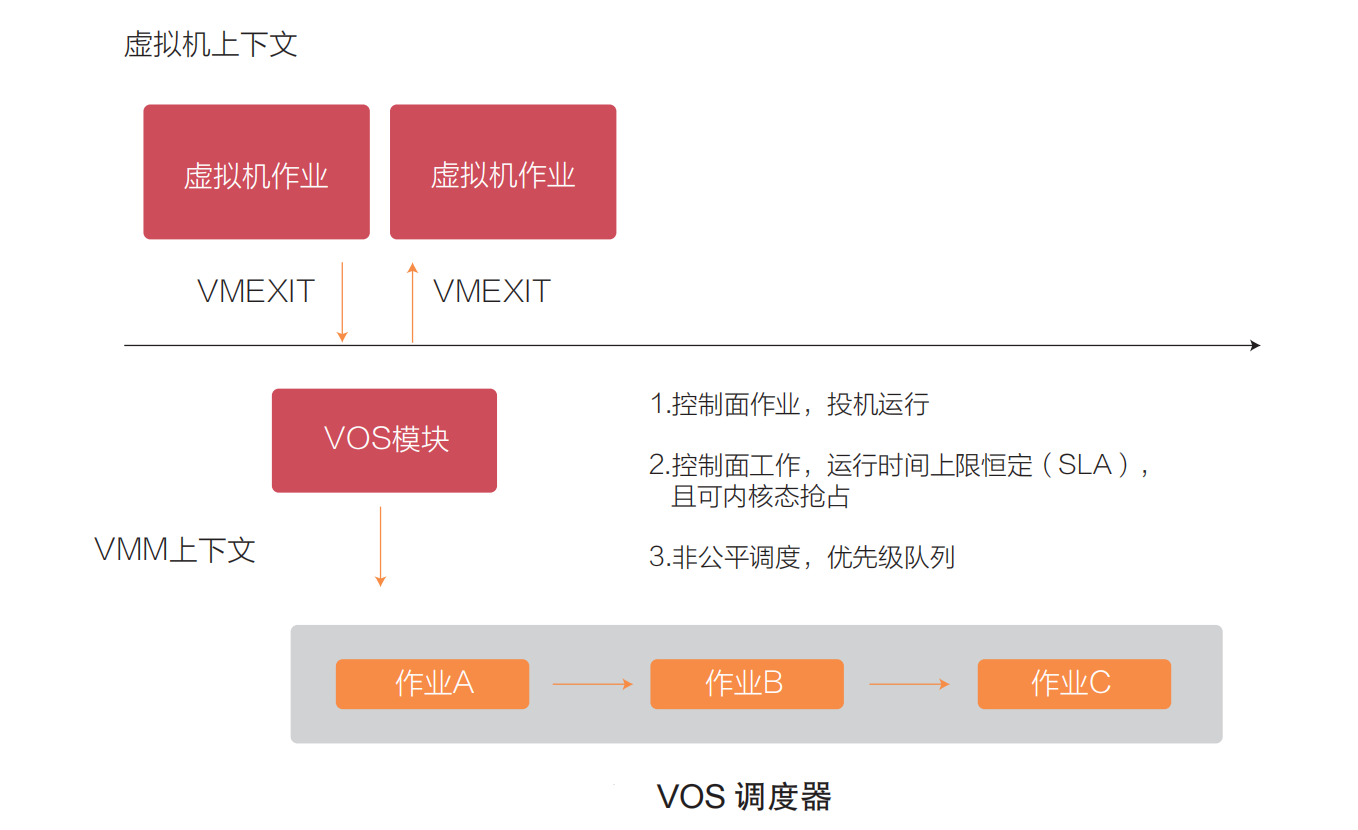 通过 VOS 调度器,虚拟 CPU 的调度延迟低到毫秒级;通过 ping flood 来测试网络 ping 的延时抖动,抖动下降到了百万分之一左右(即 ping 一百万个报文只遇到 1 个报文延迟的比例比均值明显偏大),抖动比之前的架构下降了两个数量级。在物理机上执行的控制面的作业包括:虚拟机生命周期管理、QEMU 控制线程、写日志、监控执行、包括热升级 / 热迁移在内的运维操作,在 VOS 的管理下,正在运行的虚拟 CPU 的干扰被控制在一个非常低的水平,虚拟机的计算稳定性大幅提升。
通过 VOS 调度器,虚拟 CPU 的调度延迟低到毫秒级;通过 ping flood 来测试网络 ping 的延时抖动,抖动下降到了百万分之一左右(即 ping 一百万个报文只遇到 1 个报文延迟的比例比均值明显偏大),抖动比之前的架构下降了两个数量级。在物理机上执行的控制面的作业包括:虚拟机生命周期管理、QEMU 控制线程、写日志、监控执行、包括热升级 / 热迁移在内的运维操作,在 VOS 的管理下,正在运行的虚拟 CPU 的干扰被控制在一个非常低的水平,虚拟机的计算稳定性大幅提升。
3.2 内存优化:内存分配器 VMEM 与用户态 QEMU 内存瘦身
内存分配器 VMEM 是阿里云研发的用于虚拟机内存分配的分配器,可以大幅减少内核维护的内存页表等开销(开销从以前的
1.5
%
1.5\\%
1.5% 左右下降到
0.1
%
0.1\\%
0.1% 左右),支持 1GB 的大页进一步减少 EPT 开销,实现了通过 vMCE 对硬件错误的内存页进行隔离。
在内存方面,我们通过 QEMU 对其进行瘦身,将单个虚拟机的 QEMU 进程内存开销降低到 5MB 以内,通过全新设计的用户态内存分配器避免了内存碎片,同时对不常用的内存资源进行延迟分配。
通过这两种内存优化手段,神龙虚拟化的架构比传统 KVM 虚拟化节省了约 10%的内存。
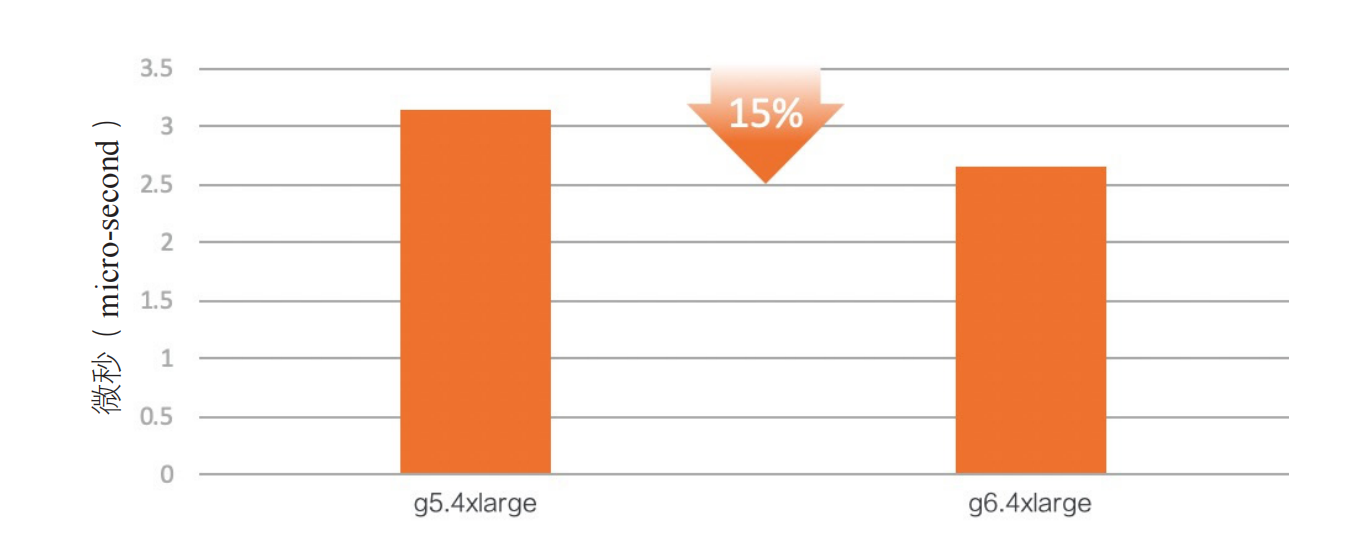
3.3 虚拟化运行加速
通过硬件加速虚拟机中的 HLT 和 MWAIT 指令,使其唤醒延迟与物理机几乎一样。同时将定时器进行硬件虚拟化,在虚拟机中访问定时器不会再触发 VMEXIT,从而提升虚拟机性能。通过这些优化,进程调度性能得到了较大提高,下图的调度延迟实测数据展示的是在某次测试中,调度两百万个进程,并统计每次调度的延迟的结果。可以看到,延迟有
15
%
15\\%
15% 的下降。图中的 g5.4xlarge 实例是之前的 KVM 架构的 ECS 虚拟机实例规格,g6.4xlarge 是神龙硬件平台下经过优化的 ECS 虚拟机实例规格。
🚀 HLT(Halt) 和 MWAIT(Monitor Wait)是 x86 架构中的两条 CPU 指令,用于管理处理器的功耗和状态。它们的主要目的是在 CPU 空闲时降低功耗,同时保持对事件的快速响应能力。
3.4 极速启动
为了让虚拟机加速启动,我们对神龙虚拟化架构也做了很多优化。
- 首先是资源的快速分配,包括实现多线程的初始化、虚拟机内存页分配时的批处理化。
- 同时对虚拟机依赖的固件进行裁剪、重构、优化,使虚拟机实现毫秒级加载。
- 我们还对一些特殊的应用场景应用了内部称为 vmfork 的技术,让虚拟机能实现秒级的快速复制。
3.5 物理机 CPU 全供给虚拟机
在传统的 KVM 虚拟化架构下,宿主机的 CPU 资源是不可能全部供给虚拟机使用的,一般还要预留 CPU 核,用于网络虚拟化软件、存储虚拟化软件、管控系统、监控脚本等的计算资源开销。
在神龙架构下,网络虚拟化和存储虚拟化都通过硬件虚拟化的方式下沉到一张 MOC 卡上,同时管控系统和绝大部分监控脚本都下沉到 MOC 卡上运行,这样物理机 CPU 资源就可以全部通过虚拟化的方式分配给虚拟机使用。经过评估,通过下沉这部分 CPU 开销到 MOC 卡上,物理机的 CPU 资源利用率能提高
10
%
10\\%
10% 左右。




评论前必须登录!
注册