 网硕互联帮助中心
网硕互联帮助中心
最近,大模型知识蒸馏技术在 AI 领域热度居高不下,尤其是随着 DeepSeek 引发广泛关注,成为行业焦点。它是一种极具价值的机器学习技术,能将预训练大型模型(教师模型)的知识迁移到小模型(学生模型)中 。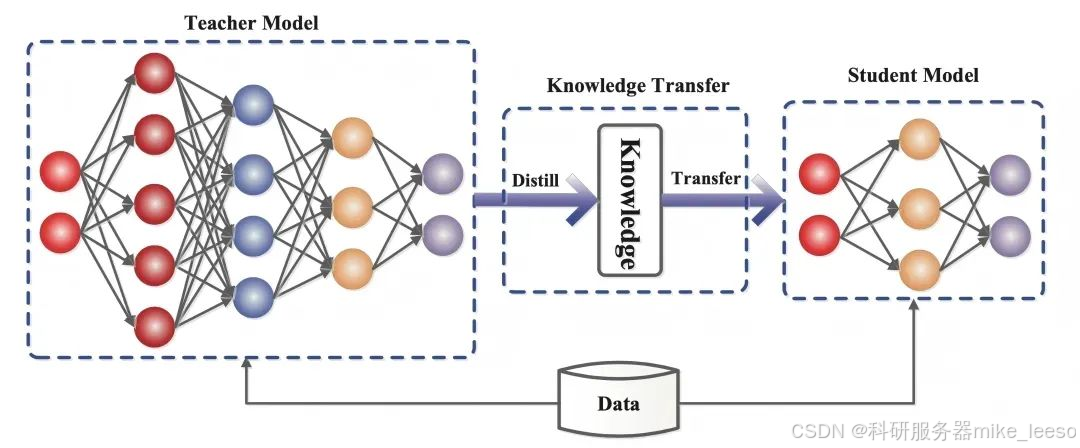
其原理是:先挑选一个泛化与表示能力出色的深度学习模型作为教师模型;让教师模型对训练数据集进行预测,生成软标签(概率分布);接着选择简易模型作为学生模型并初始化其参数;再定义像 KL 散度、交叉熵这样的损失函数,来衡量学生模型与教师模型软标签的差异,学生模型还需学习真实标签以保证准确性;通过温度参数调整软标签平滑度,温度高时利于学生模型学习泛化特征,温度低则有助于学习具体信息;最后利用损失函数指导学生模型训练,使其模仿教师模型输出,同时正确分类训练数据并持续优化。
以 DeepSeek 为例,它允许把强大的 R1 模型能力蒸馏给小模型,比如 R1-Distill-Qwen-7B,就是利用 R1 的高质量数据微调 Qwen7B 模型,显著提升了其推理能力。在 AI 大模型领域&#




评论前必须登录!
注册