 网硕互联帮助中心
网硕互联帮助中心在实验室服务器下跑通Stable-Diffusion 训练推理
- 前言
-
- 环境说明
- 1.Stable-Diffusion 模型简介
- 2.环境准备
- 3.数据准备
-
- 自定义训练数据
- Laion400M Demo 数据集
- 4.训练(单机多卡)
- 5.模型推理
前言
本文主要记录 【PaddleMIX 热身打卡】跑通 Stable-Diffusion 训练推理
的完成过程与遇到的问题及其解决方案
环境说明
本人使用MobaXterm管理实验室的Linux(别用windows,readme里说了windows系统未经测试,而且本地那张破卡也跑不动)服务器,本地使用pycharm管理代码,无可用服务器的同学推荐去AI Studio
1.Stable-Diffusion 模型简介
参考飞桨团队实现的Stable-Diffusion中的README.md
2.环境准备
用git clone 命令拉取源码,并安装环境。 实际上只需要用到PaddleMIX/ppdiffusers/examples/stable_diffusion中的项目文件,不过因为项目中的training data都需要自己下,所以仓库就几百个mb,都clone了吧。
# 克隆 PaddleMIX 仓库
git clone https://github.com/PaddlePaddle/PaddleMIX.git
# 进入stable diffusion目录
cd PaddleMIX/ppdiffusers/examples/stable_diffusion
本模型训练与推理需要依赖 CUDA 11.2 及以上版本,因此最好使用3.10以上的python
# 新建一个3.10 python环境
conda create -n paddlemix python=3.10 -y
# 安装所需的依赖, 如果提示权限不够,请在最后增加 –user 选项
pip install -r requirements.txt
以上步骤基本不会遇到任何问题
3.数据准备
你可以自定义训练数据,也可以用给的Laion400M Demo 数据集
自定义训练数据
Laion400M Demo 数据集
这部分没啥好说的,联网下个数据集完事儿
# 删除当前目录下的data(防止地址冲突)
rm -rf data
# 下载 laion400m_demo 数据集
wget https://paddlenlp.bj.bcebos.com/models/community/junnyu/develop/laion400m_demo_data.tar.gz
下好是这样的 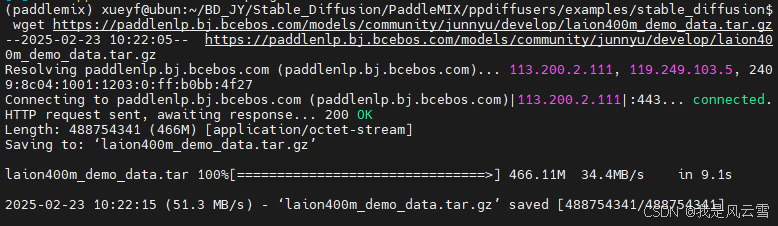
# 解压
tar -zxvf laion400m_demo_data.tar.gz
解压完是这样的 
4.训练(单机多卡)
把下段代码保存为train.sh,放进stable_diffusion文件夹,执行sh train.sh 有个细节,我没选0号gpu,因为很多人都默认用这个gpu跑一些toy_model,担心撞车,显存不够;不过也可以用nvidia-smi看一下有无占用
export FLAG_FUSED_LINEAR=0
export FLAGS_conv_workspace_size_limit=4096
# 是否开启 ema
export FLAG_USE_EMA=0
# 是否开启 recompute
export FLAG_RECOMPUTE=1
# 是否开启 xformers
export FLAG_XFORMERS=1
# 如果使用自定义数据
FILE_LIST=./processed_data/filelist/custom_dataset.filelist.list
# 如果使用laion400m_demo数据集,需要把下面的注释取消
# FILE_LIST=./data/filelist/train.filelist.list
python -u -m paddle.distributed.launch –gpus "1,2,3,4,5,6,7" train_txt2img_laion400m_trainer.py \\
–do_train \\
–output_dir ./laion400m_pretrain_output_trainer \\
–per_device_train_batch_size 32 \\
–gradient_accumulation_steps 1 \\
–learning_rate 1e-4 \\
–weight_decay 0.01 \\
–max_steps 200000 \\
–lr_scheduler_type "constant" \\
–warmup_steps 0 \\
–image_logging_steps 1000 \\
–logging_steps 10 \\
–resolution 256 \\
–save_steps 10000 \\
–save_total_limit 20 \\
–seed 23 \\
–dataloader_num_workers 4 \\
–vae_name_or_path CompVis/stable-diffusion-v1-4/vae \\
–text_encoder_name_or_path CompVis/stable-diffusion-v1-4/text_encoder \\
–unet_name_or_path ./sd/unet_config.json \\
–file_list ${FILE_LIST} \\
–model_max_length 77 \\
–max_grad_norm -1 \\
–disable_tqdm True \\
–bf16 False
报错,无’ppdiffusers’库,没关系,再装一下就好了 
pip install ppdiffusers
完事去运行又报错  查了一下,需要退化一下hugging_face包的版本
查了一下,需要退化一下hugging_face包的版本
pip install huggingface_hub=0.25.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
然后再开始训练  ok了,但是7张A600训练了两个小时才跑了百分之一,于是接下来直接用pretrained model进行推理吧
ok了,但是7张A600训练了两个小时才跑了百分之一,于是接下来直接用pretrained model进行推理吧
5.模型推理
看注释吧
from ppdiffusers import StableDiffusionPipeline, UNet2DConditionModel
# 加载公开发布的 unet 权重
unet_model_name_or_path = "CompVis/stable-diffusion-v1-4/unet"
unet = UNet2DConditionModel.from_pretrained(unet_model_name_or_path)
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", safety_checker=None, unet=unet)
# 提示词
prompt = "a photo of an astronaut riding a horse on mars" # or a little girl dances in the cherry blossom rain
# 可以通过调整参数width和height调整分辨率(但是最好保证训练分辨率和输出的分辨率一致),过大的分辨率容易爆显存
image = pipe(prompt, guidance_scale=7.5, width=512, height=512).images[0]
image.save("astronaut_rides_horse.png")
成功输出,搞定 prompt:‘a flying paddle of baidu’
觉得有用就给我github https://github.com/xueyunfeng123?tab=repositories点个星吧!!!



评论前必须登录!
注册