 网硕互联帮助中心
网硕互联帮助中心 本文还有配套的精品资源,点击获取 
简介:本文提供在Java环境下安装Memcached服务器的详细步骤,并介绍如何在项目中应用最新的Java客户端jar包,包括spymemcached和xmemcached。Memcached是一个高性能的分布式内存对象缓存系统,能够通过减轻数据库负载来提升Web应用性能。文章还会涉及Memcached的基础知识、客户端使用示例以及最佳实践,旨在帮助开发者掌握高效使用Memcached的技巧。 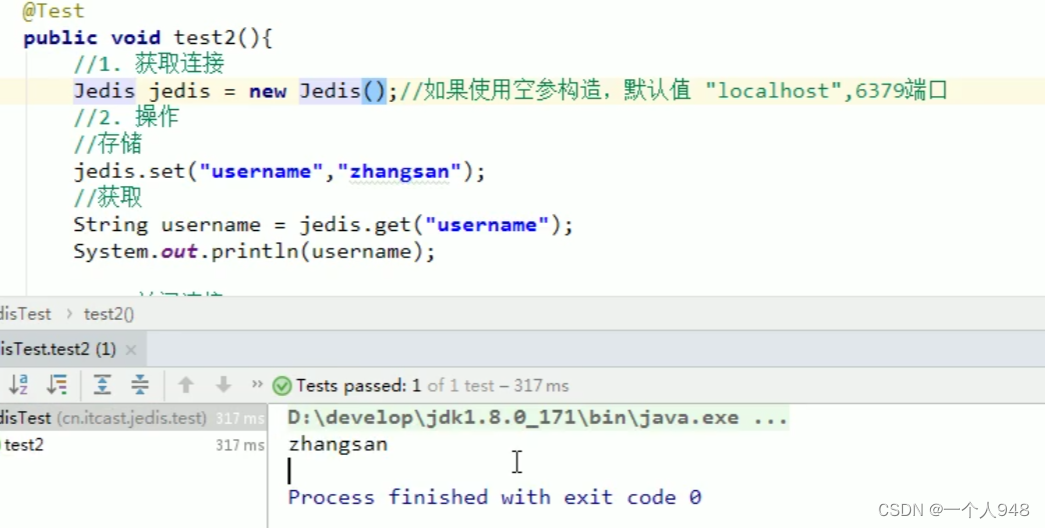
1. Memcached服务器安装步骤
Memcached作为高性能的分布式内存对象缓存系统,广泛应用于减轻数据库负载、提高访问速度等场景。在部署Memcached之前,需要进行一系列的安装步骤来确保系统的稳定运行。首先,选择适合操作系统的Memcached版本,比如Linux用户可以通过包管理器安装,Windows用户则需下载相应版本的安装包。以Linux为例,通常情况下,可以使用如下命令进行安装:
sudo apt-get update
sudo apt-get install memcached
安装完成后,可以通过启动Memcached服务来验证安装是否成功:
memcached -d
启动服务后,确保Memcached监听在正确的端口(默认为11211)上。可以使用 netstat 命令查看:
netstat -tulnp | grep memcached
以上步骤提供了一个Memcached的基本安装框架,后续章节将深入探讨Memcached的基础知识以及在Java中的应用。
2. Memcached基础知识介绍
2.1 Memcached的基本概念与作用
2.1.1 缓存原理简介
缓存是一种存储技术,用于临时存储数据以减少数据库或其他存储系统的访问次数,从而加快应用程序的响应速度。缓存的工作原理基于“局部性原理”,即在较短的时间内,程序将重复访问相同的数据集。通过缓存这些数据到快速访问的存储中,可以显著提高数据检索速度。
缓存技术通过减少数据的加载时间来提升性能,这对于Web应用程序尤其重要。Memcached作为高性能的分布式内存对象缓存系统,专门设计用来缓解数据库负载过重的问题。它通过存储键值对的数据缓存机制,能够高效地处理大量的并发连接。
2.1.2 Memcached在系统中的定位
在现代Web应用架构中,Memcached通常位于负载均衡器和后端数据库之间,作为一个分布式内存缓存层。它通过减少对数据库的直接请求次数,减轻数据库的查询压力,并且能够缓存数据库查询结果、会话信息、页面渲染结果等数据,极大地提高了系统的响应速度和可伸缩性。
Memcached也经常与其他应用服务器结合使用,例如在Web服务器前设置一个Memcached集群来缓存频繁被请求的Web内容。这样,Memcached能够提供快速的数据存取服务,而Web服务器则可以专注于处理HTTP请求和动态生成响应。
2.2 Memcached的架构与工作原理
2.2.1 内存存储机制
Memcached内部实现依赖于内存中的键值存储结构,其核心是利用哈希表来实现对数据项的快速检索。每个存储在Memcached中的数据项都有一个唯一的键和一个相关的值,键是一个字符串,值可以是任意类型的数据(通常是字符串)。
当一个数据项被存入Memcached时,系统通过哈希函数将键映射到内存中的一个位置,这个位置存储着键和值。由于这种存储方式仅使用内存,Memcached能够以非常低的延迟进行数据的读写操作。为了优化内存使用,Memcached还支持设置数据项的有效期(expirations),一旦超过有效期,数据项会被自动删除。
2.2.2 分布式存储特性
Memcached设计为一个分布式系统,能够跨越多个物理或虚拟服务器运行。当通过Memcached客户端访问缓存时,可以透明地访问集群中的任何节点,因为每个节点都是对等的,并没有一个中心化的协调器。这种分布式的特性允许Memcached集群水平扩展,即通过增加更多的节点来线性提升系统的容量和吞吐量。
为了实现分布式存储,Memcached客户端使用一致性哈希技术来选择合适的节点存储或检索数据。这种技术确保了当集群扩展或缩减时,只有很少的数据项需要迁移,从而降低了缓存失效的风险和管理开销。
2.3 Memcached的配置与优化
2.3.1 配置文件的解读
Memcached配置文件(默认名为memcached.conf)允许管理员调整服务器的行为和性能。配置文件中包含多个选项,如监听地址、端口、最大内存使用量、最大连接数等。下面是一个简单的配置文件示例:
# 启动监听的端口
-p 11211
# 最大内存使用量(MB)
-m 64
# 最大并发连接数
-c 1024
# 日志文件路径
-l ***.*.*.*
# 日志级别
-U 0
在配置文件中,可以针对不同的使用场景进行调整。例如,如果服务器内存足够大,可以增加最大内存使用量以存储更多的数据项。但如果内存较少,需要相应地减少内存限制以避免交换到磁盘,这会显著降低性能。
2.3.2 性能调优策略
性能调优是保证Memcached高效运行的关键步骤。调优通常包括调整内存分配、并发连接数和过期策略等。例如,可以通过设置合理的内存使用量来避免不必要的磁盘交换,通过调整并发连接数来平衡服务器的负载能力。
另一个重要的优化点是数据过期策略。合理设置数据的TTL(Time to Live)可以有效清理不再需要的数据,避免内存耗尽。Memcached提供了多种过期机制,包括绝对过期时间和相对过期时间,管理员可以根据实际需求进行选择。
在调整性能时,还需要注意监控Memcached的资源使用情况,包括内存占用、CPU负载和网络流量等指标。这些信息可以帮助发现潜在的性能瓶颈,并指导调优策略的制定。使用诸如 top 、 htop 、 memtier_benchmark 等工具可以监控和评估Memcached的性能表现。
3. Java Memcached客户端库概述
3.1 spymemcached客户端库
3.1.1 spymemcached的特点与优势
spymemcached是由Danga Interactive开发的Java客户端库,它以简洁的API和良好的性能而著称。该客户端特别适合用于大型分布式部署的环境,支持高并发和低延迟的场景。与其他客户端库相比,spymemcached的优势在于:
- 非阻塞I/O,提供高效的网络通信
- 支持分布式哈希表(DHT),容易实现Memcached节点的扩展
- 内部连接池复用,减少连接开销
- 对操作失败的重试机制,提高应用的健壮性
- 支持多种协议,包括文本协议和二进制协议
3.1.2 spymemcached的安装与基本使用
为了在Java项目中使用spymemcached客户端库,您需要添加相应的依赖到您的项目中。如果使用Maven作为构建工具,可以在pom.xml文件中添加以下依赖:
<dependency>
<groupId>com.github.spymemcached</groupId>
<artifactId>spy-memcached</artifactId>
<version>2.12.3</version>
</dependency>
安装完成后,可以按照以下步骤进行基本的使用:
下面是一个使用spymemcached进行连接和存取数据的示例代码:
import net.spy.memcached.*;
public class SpymemcachedExample {
public static void main(String[] args) throws Exception {
// 创建一个连接服务器列表
MemcachedClientBuilder builder = new ConnectionFactoryBuilder()
.setProtocol(Protocol.BINARY)
.setFailureMode(FailureMode.REDIRECT)
.setTranscoder(new SerializingTranscoder())
.setOpTimeout(5000)
.setReadTimeout(5000)
.setRetryDelay(500)
.setServerFailoverTime(1000)
.setLocatorType(Locator윤.Default);
// 构建连接池
ConnectionPool connectionPool = new ConnectionPoolImpl(builder, 10, 1000);
MemcachedClient client = new MemcachedClient(connectionPool);
// 连接到服务器
client.addServer("localhost", 11211);
// 存储数据
client.set("key", 90, "value");
// 获取数据
String value = client.get("key");
System.out.println(value);
// 关闭连接
client.shutdown();
}
}
上述代码中创建了一个Memcached客户端实例,并连接到了本地运行的Memcached服务。然后设置了一个键值对到缓存中,接着从缓存中获取这个键对应的值并打印出来,最后关闭了客户端连接。
3.1.3 spymemcached的核心架构解析
spymemcached的核心架构基于 MemcachedClient , Transcoder , ConnectionFactory 等组件构成。
- MemcachedClient : 客户端的主接口,提供了各种缓存操作的方法,如存取数据、移除数据等。
- Transcoder : 负责数据的序列化与反序列化,使得用户可以存储自定义对象到Memcached服务器上。
- ConnectionFactory : 用于创建底层网络连接,支持多种协议和网络配置。
spymemcached还提供了连接池机制,以减少重复创建连接的开销,优化了性能。同时,它支持通过事件监听器来处理各种网络事件,比如连接建立与断开,命令执行完成等。
通过了解spymemcached的架构和组件,开发者可以更好地理解其工作原理和使用方式,进一步优化Memcached的性能。
3.2 xmemcached客户端库
3.2.1 xmemcached的特点与优势
xmemcached是一个纯Java实现的Memcached客户端库,它在功能丰富度、性能和稳定性上都有不俗的表现。xmemcached提供了以下一些优势:
- 支持自动重连和节点健康检查机制
- 兼容标准的Memcached协议,并且支持文本和二进制协议
- 支持Java NIO,实现非阻塞I/O
- 可配置的连接池,以及灵活的线程池设置
- 具备出色的扩展性和维护性
3.2.2 xmemcached的安装与基本使用
和spymemcached类似,要在Java项目中使用xmemcached,首先需要添加Maven依赖:
<dependency>
<groupId>com.googlecode.xmemcached</groupId>
<artifactId>xmemcached</artifactId>
<version>3.3.0</version>
</dependency>
安装完成之后,下面是一个使用xmemcached进行基本连接和数据存取操作的示例:
import net.rubyeye.xmemcached.MemcachedClient;
import net.rubyeye.xmemcached.XMemcachedClientBuilder;
import net.rubyeye.xmemcached.exception.MemcachedException;
import java.util.concurrent.TimeUnit;
public class XmemcachedExample {
public static void main(String[] args) throws MemcachedException {
MemcachedClient client = new XMemcachedClientBuilder(
"localhost:11211").build();
// 设置超时时间为5秒
client.setConnectionPoolTimeout(5, TimeUnit.SECONDS);
// 存储数据
client.set("key", 0, "value");
// 获取数据
String value = client.get("key");
System.out.println(value);
// 关闭连接
client.shutdown();
}
}
这段代码展示了如何创建一个xmemcached的客户端实例,并与本地的Memcached服务器进行连接。之后,它使用客户端实例存储了一个字符串值,并从缓存中检索它,最后关闭了连接。
xmemcached库可以很容易集成到Spring框架中,并支持使用Guice、Spring等方式进行依赖注入。它还提供了丰富的配置选项,以满足不同环境下的需要。
3.2.3 xmemcached的核心架构解析
xmemcached的核心组件包括 MemcachedClient , MemcachedTranscoder ,以及 XMemcachedClientBuilder 等。
- MemcachedClient : 作为客户端的主要接口,负责调用Memcached的各个命令,并且提供了线程安全的缓存操作方法。
- MemcachedTranscoder : 负责对数据进行序列化和反序列化操作,支持Java基本类型、对象和集合等数据结构。
- XMemcachedClientBuilder : 用于构建 MemcachedClient 实例,提供配置选项和连接池管理。
xmemcached内部使用Java NIO的 Selector 模型,可以处理大量的并发连接。它也支持自定义 Transcoder 实现,方便存储自定义对象。xmemcached通过配置项,允许用户细粒度地调整连接参数,包括最大连接数、连接超时、重试次数等。
xmemcached的架构设计让其具有很好的扩展性,可以容易地添加新的协议支持或实现特定的功能。此外,xmemcached的内部结构使得其可以快速地对Memcached协议进行更新,并且可以很快地适应新版本的Memcached服务器。
通过本文对Java Memcached客户端库的概述,希望读者能够对如何选择和使用Memcached客户端库有一个初步的认识。接下来的章节将深入介绍如何在Java项目中添加Memcached客户端jar包,以及如何进行Memcached数据存取操作。
4. 客户端jar包的添加和使用方法
4.1 如何在Java项目中添加jar包
4.1.1 Maven依赖管理
在使用Maven作为项目管理工具的Java项目中,添加Memcached客户端库非常便捷。首先,需要在项目的 pom.xml 文件中添加对应的依赖。例如,要添加xmemcached客户端库,可以添加以下依赖:
<dependencies>
<!– xmemcached client –>
<dependency>
<groupId>com.google.code.xmemcached</groupId>
<artifactId>xmemcached</artifactId>
<version>2.4.5</version>
</dependency>
</dependencies>
在添加完毕后,运行Maven的 mvn clean install 命令,以确保所有依赖都被下载并安装到本地仓库中。Maven会自动处理jar包及其依赖的下载与管理,这简化了开发者的操作流程。
4.1.2 手动添加jar包及其依赖
如果不使用Maven或其他依赖管理工具,手动添加jar包及其依赖也是可行的。首先,需要从官方或其他源下载客户端库的jar文件以及所有必需的依赖jar文件。接着,将这些jar文件复制到项目的 lib 目录下(如果不存在,需要创建一个)。
之后,在IDE中进行配置,通常是在项目的构建路径设置中,将这些jar文件添加到项目的类路径中。这样做可以确保在编译和运行项目时,Java虚拟机能够找到所需的库。
4.2 Memcached客户端的初始化与连接
4.2.1 连接池的配置与管理
Memcached客户端的连接管理对于性能至关重要。xmemcached客户端库提供了连接池的支持,可以配置连接池来提高性能和可靠性。以下是配置连接池的一个例子:
ClientConfig clientConfig = new ClientConfig();
clientConfig.setConnectionPoolSize(10); // 设置连接池大小为10
clientConfig.setUseNagleAlgorithm(false); // 禁用Nagle算法以减少延迟
clientConfig.setSocketConnectTimeout(1000); // 设置连接超时时间
clientConfig.setSessionIdleTimeout(1800); // 设置会话空闲超时时间
// 使用ClientConfig构建MemcachedClient实例
MemcachedClient client = new MemcachedClient(clientConfig, addresses);
在代码中,我们创建了 ClientConfig 对象,并对其进行了一系列配置,比如设置连接池大小、是否使用Nagle算法、连接超时时间以及会话空闲超时时间。配置完成后,我们利用这个配置对象和服务器地址列表创建了 MemcachedClient 实例。
4.2.2 客户端的生命周期控制
客户端的生命周期控制涉及到客户端实例的创建、使用和关闭。为了确保资源得到恰当的管理,使用try-with-resources语句可以确保即使在出现异常的情况下,资源也能被正确关闭。下面是一个简单的例子:
try (MemcachedClient client = new MemcachedClient()) {
// 使用client进行数据存取操作
} catch (IOException e) {
// 处理异常
}
在这个例子中,当try代码块结束时, MemcachedClient 实例会自动关闭,释放所有资源。这是管理资源的推荐方式,因为它既简洁又有效。
在第四章中,我们介绍了如何在Java项目中添加Memcached客户端库jar包,并讲解了如何通过Maven或手动方式添加依赖。然后,我们深入了解了客户端的初始化和连接管理,特别是连接池的配置和客户端生命周期的控制。这些内容对于理解和应用Memcached客户端至关重要,能够帮助开发者更高效地利用Memcached进行性能优化。在下一章节中,我们将具体展示如何使用Memcached进行基本的数据存取操作,以及高级的数据操作技术。
5. Memcached数据存取操作示例
5.1 基本数据存取操作
5.1.1 数据的设置(set)与获取(get)
Memcached提供了简单的键值存储方式,我们可以使用set方法来存储数据,并通过get方法来检索数据。下面将详细介绍这些基本操作的实现。
首先,我们来看一下set方法的基本语法:
public void set(Serializable key, Serializable value, int expiry)
这个方法接受三个参数: – key:作为数据访问的标识符,必须是Serializable类型。 – value:实际存储的数据,必须是Serializable类型。 – expiry:数据的有效期,单位为秒。如果设定为0,则表示不设置过期时间。
下面是一个set方法使用示例:
import net.spy.memcached.MemcachedClient;
public class MemcachedExample {
public static void main(String[] args) throws Exception {
MemcachedClient client = new MemcachedClient(new InetSocketAddress("localhost", 11211));
// 存储数据
client.set("key1", "value1", 0);
// 获取数据
String value = (String) client.get("key1");
System.out.println(value);
}
}
在上面的代码中,首先创建了一个MemcachedClient实例,连接到本地的11211端口(这是Memcached的默认端口)。然后,我们使用set方法存储了一个键为"key1"、值为"value1"的字符串,并没有指定过期时间。接着,我们使用get方法获取并打印了这个键对应的值。
5.1.2 增加(add)、替换(replace)与删除(delete)
除了基本的set和get操作,Memcached还提供了其他的数据操作方法,如增加(add)、替换(replace)和删除(delete)。
- 增加(add):仅当指定的键不存在时,才添加新的键值对。
- 替换(replace):只有当指定的键存在时,才更新其对应的值。
- 删除(delete):删除指定键的数据。
下面是这些操作的使用示例:
// 增加操作示例
client.add("key2", "value2", 0);
// 替换操作示例
client.replace("key1", "new_value", 0);
// 删除操作示例
client.delete("key2");
在增加操作中,如果"key2"已经存在,则操作失败。替换操作只有当"key1"存在时才会更新它的值为"new_value"。删除操作会移除"key2"对应的键值对。
5.2 高级数据存取操作
5.2.1 多键操作与批量处理
Memcached客户端还支持对多个键进行操作,这包括了批量设置(setMulti)、批量获取(getMulti)以及批量删除(deleteMulti)等。批量操作可以一次性处理多个键值对,从而提高效率。
这是批量设置(setMulti)方法的基本使用:
import java.util.HashMap;
import java.util.Map;
// 构建一个键值对映射
Map<String, String> items = new HashMap<>();
items.put("key3", "value3");
items.put("key4", "value4");
// 批量设置
client.setMulti(items);
在上述代码中,我们首先创建了一个包含多个键值对的Map对象,然后使用setMulti方法将它们批量存储到Memcached中。
批量获取(getMulti)方法则可以一次性获取多个键对应的值:
// 批量获取
Map<String, String> values = client.getMulti(new String[]{"key1", "key3", "key4"});
在这个例子中,我们通过getMulti方法并传入一个包含多个键的数组来批量获取这些键对应的值。
5.2.2 过期策略与数据持久化
Memcached中的数据可以设置过期时间,这样可以在数据不再需要时自动删除,保持缓存的数据是最新的。默认情况下,如果设置的过期时间是0,数据将永不过期。
下面是设置不同过期时间的示例:
// 设置数据30秒后过期
client.set("key5", "value5", 30);
// 设置数据1分钟后过期
client.set("key6", "value6", 60);
虽然Memcached是内存中的缓存系统,因此不具备持久化存储的能力,但如果需要持久化功能,需要考虑结合其他存储方案,比如定期将数据写入到数据库中。
在实际应用中,可以通过设置合理的过期时间,以及结合持久化存储策略来保证数据的可靠性和一致性。
6. Memcached使用最佳实践
在深入理解了Memcached的安装、配置以及客户端使用之后,我们已经具备了将Memcached有效地集成到我们的应用中的能力。但是为了确保缓存系统稳定高效地运行,我们需要掌握一些最佳实践,这包括解决在实践中可能遇到的常见问题,性能监控,日志分析,以及与其他缓存方案的比较。
6.1 Memcached常见问题解决方案
6.1.1 内存溢出与数据一致性问题
随着缓存数据的不断增长,Memcached可能会遇到内存溢出的问题。为了避免这种情况的发生,可以通过合理配置最大内存(-m 参数)以及淘汰策略(-M 参数)来控制。
在数据一致性方面,由于Memcached本身是分布式缓存,不保证数据的持久性。因此,在更新数据时,你需要使用一些策略,例如设置合理的过期时间(TTL),或是在数据变更时删除相关的缓存项。
6.1.2 集群部署与故障转移策略
Memcached的集群部署可以通过增加节点来提高缓存的可用性和容量。故障转移策略是集群部署中必须考虑的,可以通过客户端实现故障节点的自动感知和切换,或者使用专门的代理软件来管理节点故障转移。
在集群配置中,合理的节点数量和分布策略对于负载均衡和系统稳定至关重要。通常采用一致性哈希算法来分配数据到不同的节点,减少因节点增减导致的大规模数据迁移。
6.2 Memcached性能监控与日志分析
6.2.1 性能监控指标
在生产环境中,性能监控是确保Memcached高效运行的关键。监控指标可以包括但不限于:
- 内存使用率
- 命中率(Hit Ratio)
- 设置和获取操作的响应时间
- 连接数
- 过期和删除项的数量
这些指标可以通过内置的统计命令 stats 获得,也可以集成外部监控工具如Prometheus和Grafana进行实时监控。
6.2.2 日志分析工具与方法
Memcached的日志记录了各种事件和错误信息,合理地分析这些日志可以帮助我们诊断问题。常用的工具包括 memtier_benchmark ,可以用来模拟负载并记录操作日志,以及使用日志分析工具如ELK(Elasticsearch, Logstash, Kibana)堆栈来分析和可视化日志数据。
在分析日志时,应该关注如下的关键信息:
- 错误和警告消息
- 连接和断开的客户端统计
- 操作性能分布和异常情况
6.3 Memcached与其他缓存方案比较
6.3.1 与Redis的对比分析
Memcached和Redis是目前广泛使用的两种缓存系统。它们之间有一些关键的区别:
| 特性 | Memcached | Redis | |———–|———————|———————-| | 数据类型 | 仅支持简单的key-value| 支持string, hash, list, set, sorted set等 | | 持久性 | 不支持 | 支持数据持久化到磁盘 | | 事务性 | 不支持 | 支持 | | 数据过期 | 支持 | 支持 | | 内存管理 | LRU淘汰策略 | 可以配置不同的淘汰策略 |
从上表可以看出,Redis提供了比Memcached更丰富的数据结构和操作,同时支持数据的持久化,适合需要复杂数据结构和持久化需求的应用场景。然而,如果你的应用仅需要一个快速的键值存储,Memcached可能是更轻量级的选择。
6.3.2 与Ehcache的对比分析
Ehcache是一个纯Java实现的本地缓存解决方案,和Memcached相比,它提供了以下不同之处:
| 特性 | Memcached | Ehcache | |———–|———————|———————-| | 缓存位置 | 分布式缓存 | 本地缓存或分布式缓存 | | 数据持久化 | 不支持 | 支持文件或数据库存储 | | 平台支持 | 跨平台 | 仅限Java环境 | | 数据过期 | 支持 | 支持 |
Ehcache的优势在于它的本地缓存能力,对于单个JVM进程的应用性能提升非常明显。同时,Ehcache的数据持久化能力也使得它可以用于持久化缓存数据。然而,Ehcache不支持跨JVM的分布式缓存,而这一点正是Memcached的强项。
通过上述对比,我们可以看到不同的缓存解决方案有其各自的特点和优势,选择哪一种主要取决于实际的应用需求和场景。在决定使用Memcached时,我们需要根据实际的需求来权衡其优缺点,并结合最佳实践来确保应用的高性能和稳定性。
本文还有配套的精品资源,点击获取
简介:本文提供在Java环境下安装Memcached服务器的详细步骤,并介绍如何在项目中应用最新的Java客户端jar包,包括spymemcached和xmemcached。Memcached是一个高性能的分布式内存对象缓存系统,能够通过减轻数据库负载来提升Web应用性能。文章还会涉及Memcached的基础知识、客户端使用示例以及最佳实践,旨在帮助开发者掌握高效使用Memcached的技巧。
本文还有配套的精品资源,点击获取




评论前必须登录!
注册