 网硕互联帮助中心
网硕互联帮助中心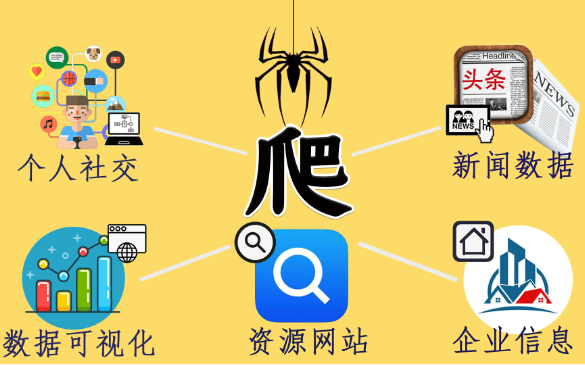
在当今的数字时代,数据已经成为了一种宝贵的资源,而爬虫作为一种能够自动抓取互联网数据的工具,也越来越受到人们的关注。本文将为您详细解析爬虫的含义,以及爬虫服务器在爬虫工作中的作用。
一、爬虫的含义
爬虫,又称网络爬虫,是一种按照一定的规则自动抓取互联网信息的程序。爬虫可以模拟人类浏览网页的行为,通过发送请求来获取网页内容,并按照特定的算法分析、提取所需的数据。爬虫可以帮助人们快速地获取大量数据,提高工作效率,因此在数据挖掘、舆情监测、竞品分析等领域得到了广泛的应用。
二、爬虫服务器的功能
爬虫服务器是专门为爬虫工作提供支持的服务器,其功能主要包括以下几个方面:
1. 数据抓取:爬虫服务器可以按照预设的规则自动抓取互联网上的网页数据,并将数据存储到本地或者数据库中。
2. 数据分析:可以对抓取的数据进行分析,提取有用的信息,为后续的数据处理提供支持。
3. 数据存储:可以将抓取的数据存储到本地或者数据库中,方便后续的数据处理和分析。
4. 模拟请求:可以模拟用户的请求,进行模拟访问和测试,提高爬虫工作的效率和准确性。
5. 数据保护:爬虫应当遵守相关法律法规和网站的robots协议,尊重网站的知识产权和隐私权,避免过度抓取和滥用数据。
综上所述,爬虫服务器在爬虫工作中扮演着至关重要的角色,它能够提高数据抓取的效率和准确性,为后续的数据处理和分析提供有力的支持。在使用爬虫和爬虫服务器时,我们应该遵守相关法律法规和网站的规定,尊重网站的知识产权和隐私权,避免滥用数据和违反法律规定。







评论前必须登录!
注册