 网硕互联帮助中心
网硕互联帮助中心第一步:登录autodl平台选择适合自己的GPU服务器(可以进行学生认证)
(1)autodl官网网址:AutoDL算力云 | 弹性、好用、省钱。租GPU就上AutoDL
注意这个算力平台经常出现实例被租完的情况,本人的建议是假如你第二天要用,那你今天晚上0点的时候就登陆进来,这个时候会有不少实例被释放,然后最好多选择几个实例,避免第二天出现GPU不足的情况。

(2)然后我选择的是基础镜像,也就是自己装环境,选择合适的pytorch版本

(3)创建开机
(4) 点击控制台
(5)点击容器实例
(6)点击开机(我建议选择无卡开机,也就是点击更多,点击无卡开机),无卡开机意思就是此时你不占用GPU资源,容易出现的问题就是上文我说的下次选择有卡开机时,GPU被别人占了,这个时候就非常难崩了,但好处就是一个小时一毛钱,花起来不心疼,因为你要进行比较长时间的数据传输,尤其是你数据集非常大的时候(比如我18万张三通道png图像)
(7)把相关的登录指令和密码复制到笔记中,便于查看复制

第二步:配置环境(接下来开始一边进行环境的配置,一边进行数据的传输(因为我是学硬件IC的,对于并行效率比较在意,哈哈哈,当然你也可以一项干完再干另一项)
(1)点击jupyter lab,然后点击终端,进入如下界面
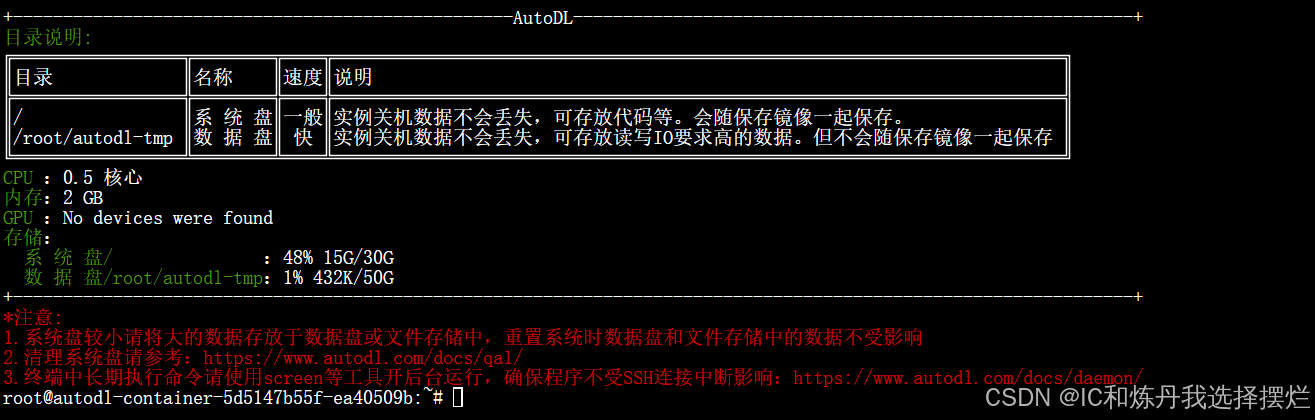
(2)然后开始Linux指令进行创建自己的conda库(对于经常炼丹的朋友来说,windows系统的操作肯定不陌生,现在进行Linux端的指令)
(3)先输入指令:vim ~/.bashrc,进入如下所示:
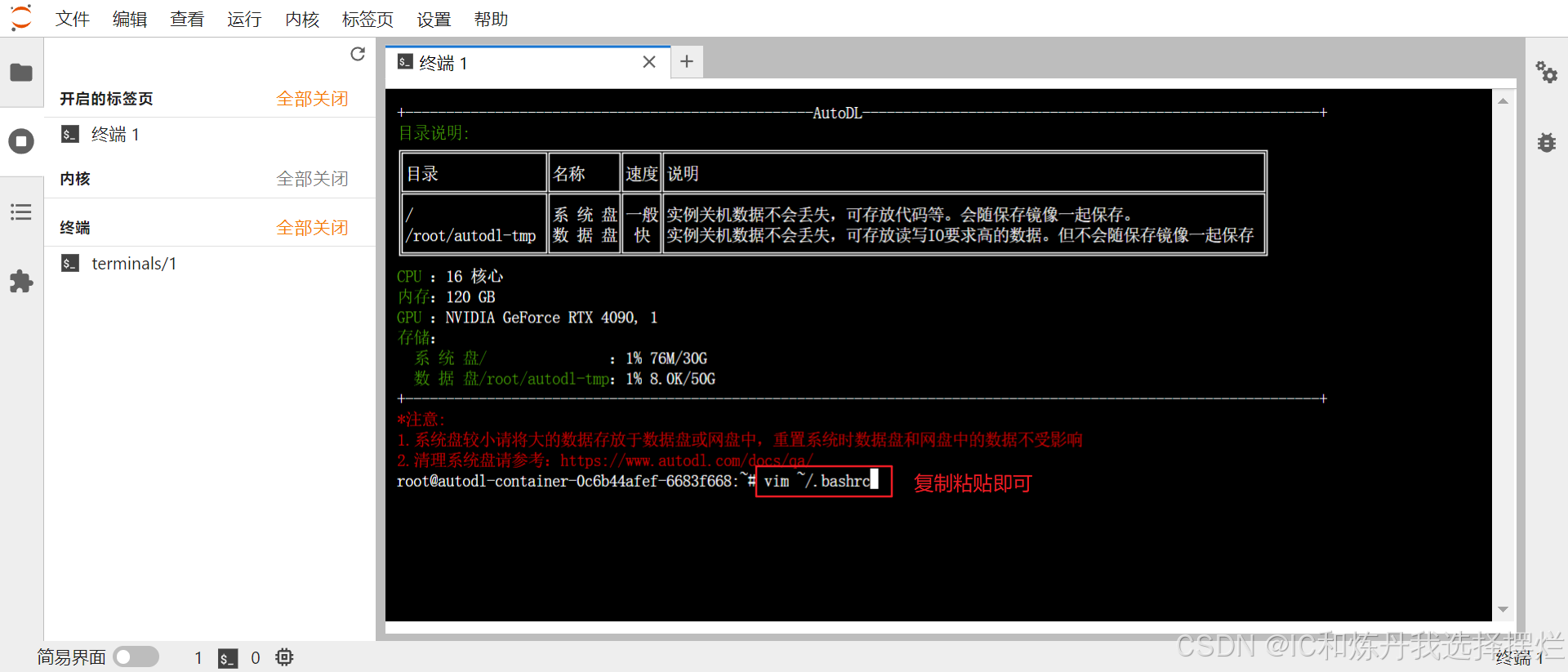
(4)按下回车,进入下图
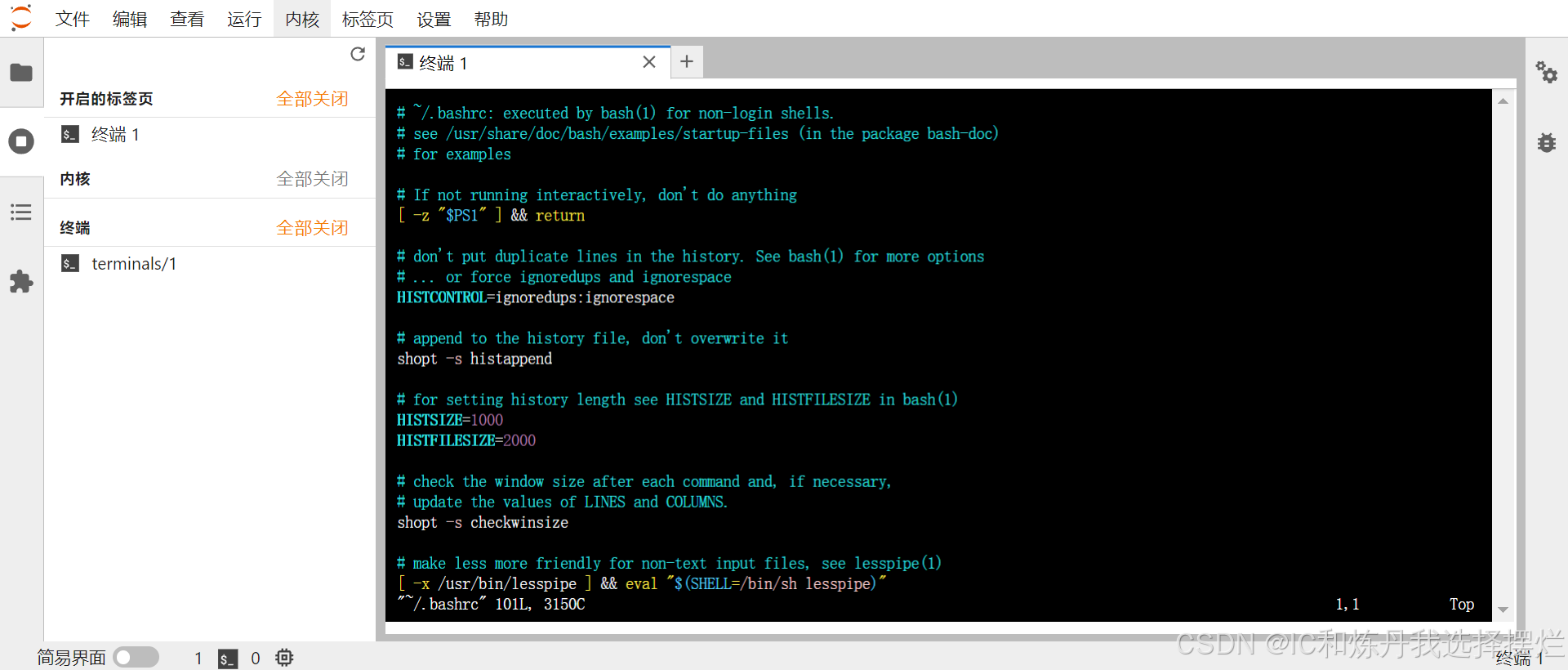
(5)按键盘上i键,变化也就是多了一行,然后滑动滚轮,到现在代码的最后一行最后一列

(6) 按回车到下一行,输入source /root/miniconda3/etc/profile.d/conda.sh

(7)输入之后按下ESC键,到下一行,然后输入:wq
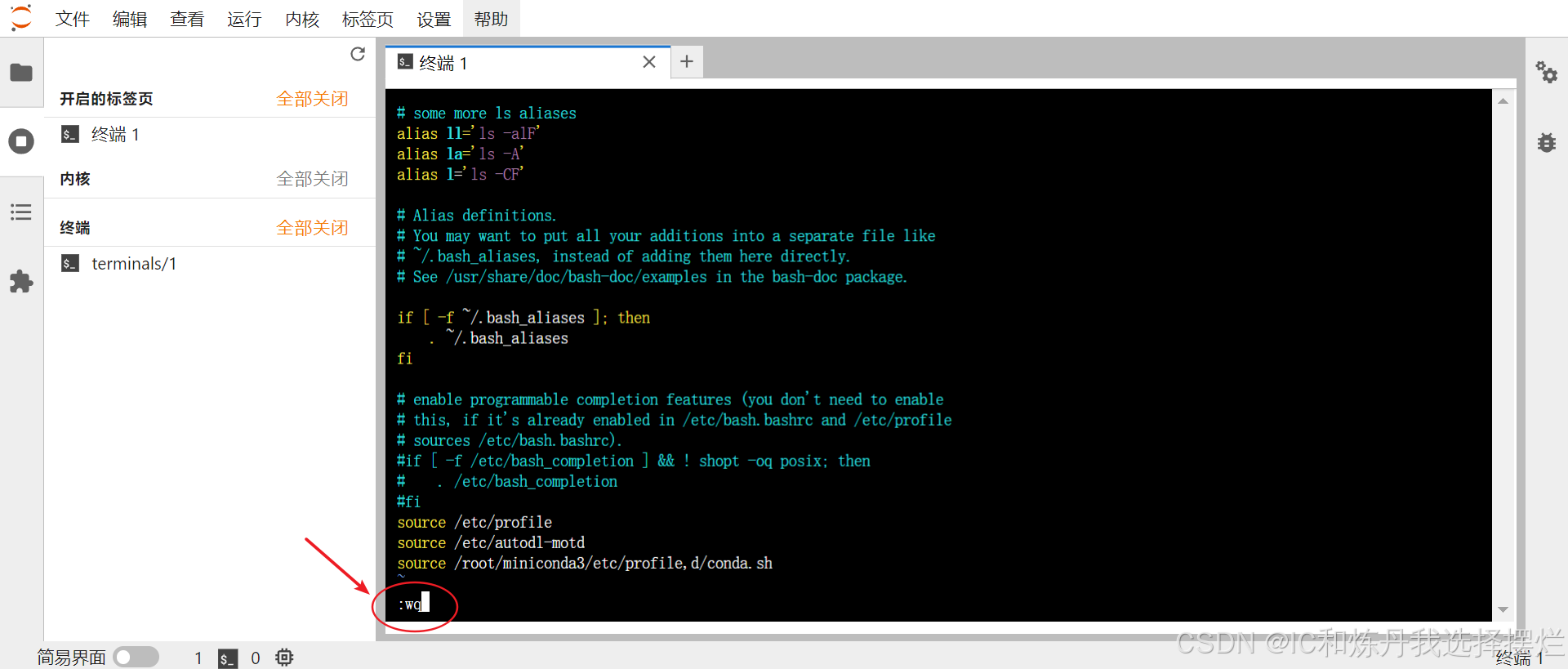
(8)按下回车 ,结束,回到刚开始的界面
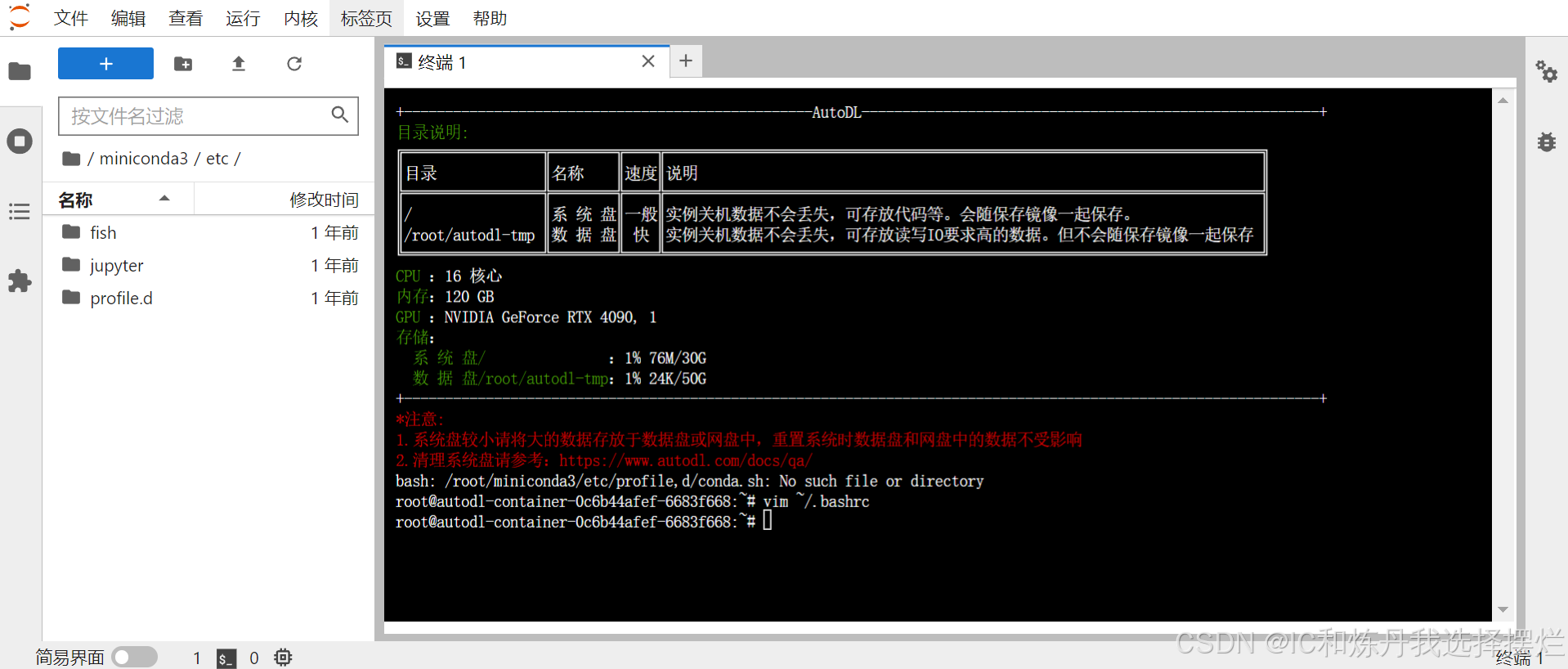
(9)然后输入bash,按下enter,进行刷新一下
(10)建立自己的虚拟环境,输入指令:conda create -n jy python=3.10(此处的jy是你自己命的名字)
(11)接下来就跟软件端一致了,按y,虚拟环境创建好了
(12)然后进入虚拟环境:conda activate jy
(13)此时你可以完全在此个虚拟环境里装库了
(14)最关键的是第四步要把这个在远端服务器建的虚拟环境加载出来,选择正确,用于训练
第三步:上传数据(与远端服务器进行实时的交互)
(1)我建议下载如下两个软件,可以进入软件官网进行下载

(2)下载安装完之后(没有额外的步骤,就安装,一直点我同意,下一步就可以),先打开红色的,点击新建会话

(3)协议选择SSH
(4)主机就是上文复制到笔记中的

(5)填写完整之后,点击确定,点击确定之后要填用户名称(一律都是root)和密码(如上图片),之后点击新建文件传输

(6)开始文件的传输,先设置好文件的相关映射

(7) 至此,完成文件的上传,由于我的数据集比较大,做图像推理部署的,所以这里大概要等挺长时间,所以此时就可以与第二步并行进行。
第四步:pycharm连接(至关重要,关系能不能正确连接到你上文所做的那一切,如果连接错误,会很焦灼的,别问我怎么知道的)
(1)下载专业版pycharm(社区版不具备ssh功能)(学生可以学生认证,免费使用一年)
(2)然后打开自己的项目,点击右下角
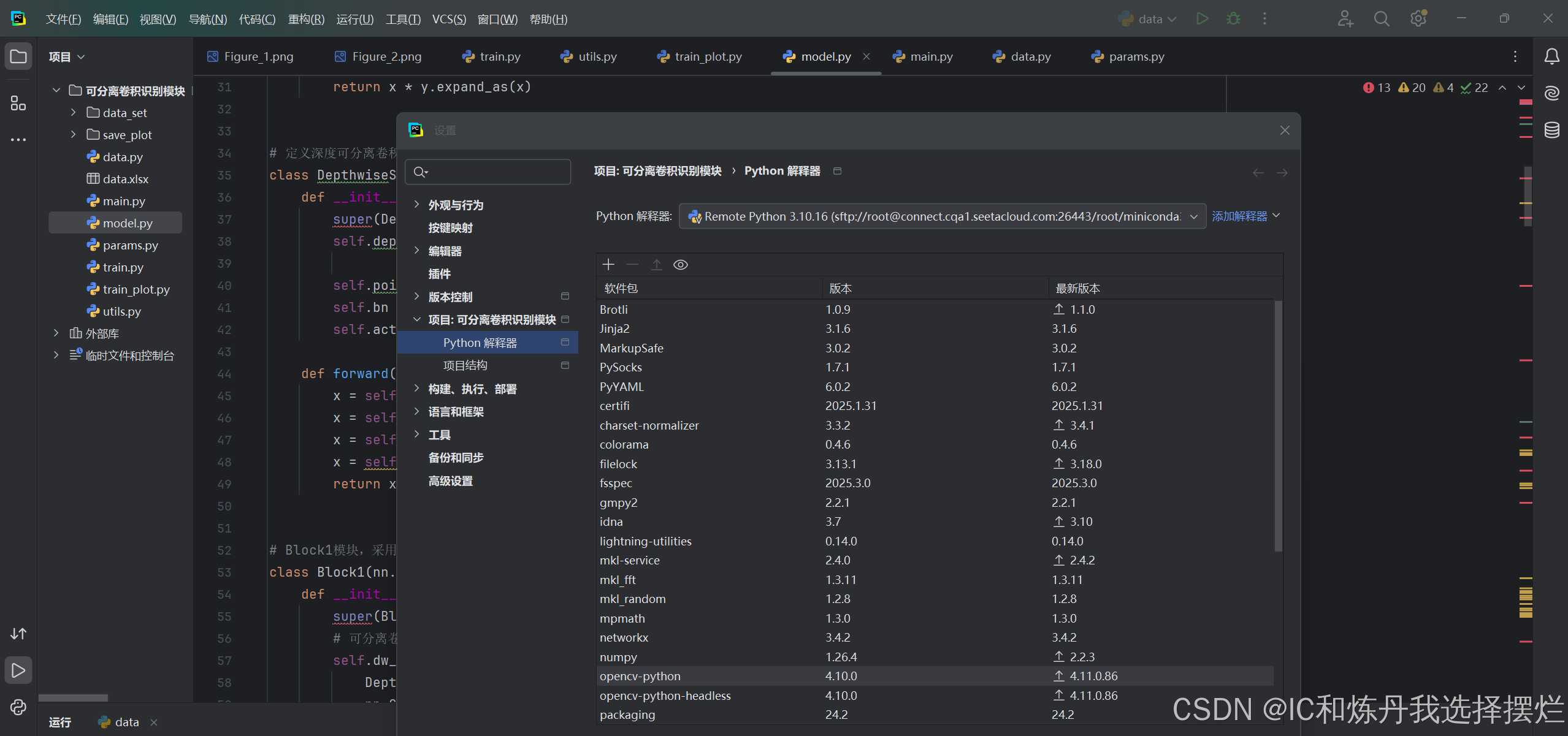
(3)点击添加新的解释器

(4) 选择于ssh
(5)填写相关的信息(上文已经说过)
(6) 点击下一步,输入密码,然后再进行下一步,最关键的就是4/4
(7)一定要选择系统解释器,不是第一个!!
(8)解释器的位置选择:root—>miniconda3—>envs—>jy(你刚才建立的虚拟环境的名称)—>bin—>python(我选的python3.10)
(9)同步文件夹,选择第三步的二者相对应的位置
(10)至此,完成了全部,不过你需要等待解释器的更新传递(有可能比较慢),还有数据集的同步,我这太大了,导致很慢,可以选择无卡开机,上传会快一点
(11)点击文件(files)——>设置(settings)——>项目:可分离卷积——>python解释器,观看软件包,若有你在远端服务器conda装的所有包,证明成功
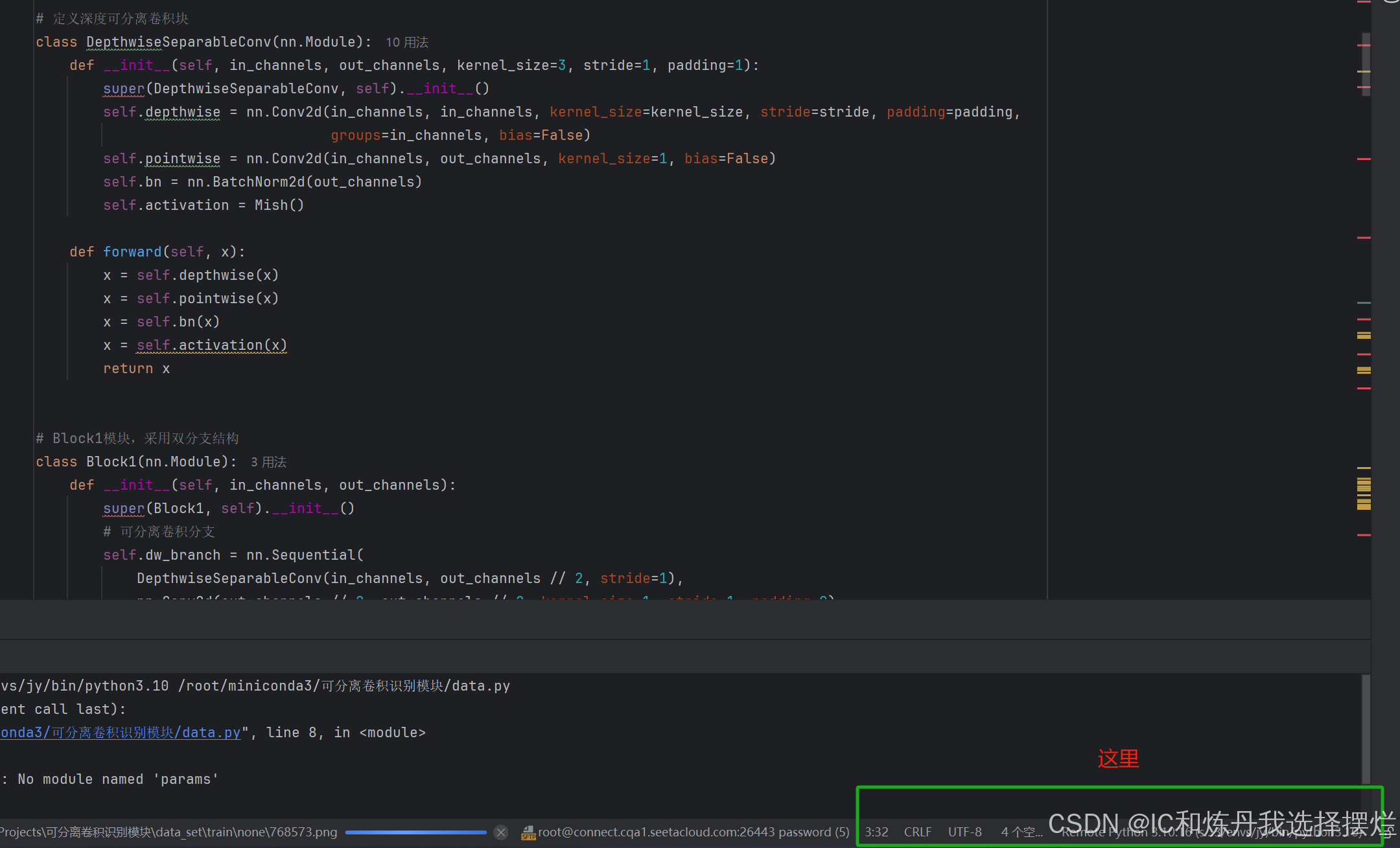
(12)我的还爆红估计是没反应过来,不同步,实际运行错误不会是少库了
(13)提示一点,这个模型一定要改成相对路径,不要使用绝对路径。
(13)之后用GPU调试模型就OK了,修改模型让其参数量下降(深度可分离卷积),但是准确度肯定有影响,这时可以选择双分支结构等等修改网络结构,深度可分离卷积的参数量大大减少,极大的减少了资源消耗,在FPGA端部署有明显优势。

![[已解决·实验日志] AutoDL系统盘异常爆满,原因是PyCharm 在连接到远程服务器调试时,自动执行后台任务(正在更新 python解释器), 将某些包&依赖项下载到了服务器上-网硕互联帮助中心](https://www.wsisp.com/helps/wp-content/uploads/2025/04/20250419204602-68040b8ac23b2-220x150.png)

评论前必须登录!
注册