 网硕互联帮助中心
网硕互联帮助中心文章目录
- 0 DeepSeek系列总览
- 1 模型架构设计
-
- 基本参数
- 专家混合模型(MoE)[DeepSeek-V2提出, DeepSeek-V3改良]
- 多头潜在注意力(MLA)[DeepSeek-V2提出]
- 多token预测(MTP)[DeepSeek-V3提出]
- 2 DeepSeek-R1-Zero及DeepSeek-R1的训练策略
-
- DeepSeek-R1-Zero with RL only
- DeepSeek-R1 with Both RL and SFT
- FP8混合精度量化 [DeepSeek-V3提出]
- 知识蒸馏 [DeepSeek-R1提出]
- DeepSeek-R1的一些失败尝试
-
- 过程奖励模型(PRM)
- 蒙特卡洛搜索树(MCTS)
- 3 Infrastructures [DeepSeek-V3提出]
-
- 计算集群
- 训练框架
-
- DualPipe和计算-通信overlap
- 跨节点all-to-all通信
- 节省显存
- 推理和部署
-
- Prefill阶段(compute bound)
- Decoding阶段(memory bound)
- 训练成本
- DeepSeek-R1开源复现项目汇总
0 DeepSeek系列总览
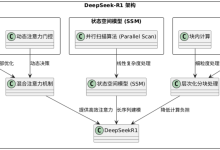
DeepSeek-R1基于DeepSeek-V3-Base模型,提出了一系列训练策略,包括基于纯强化学习的训练(DeepSeek-R1-Zero)、基于多阶段的训练和冷启动(DeepSeek-R1)、知识蒸馏等。下面是我总结的DeepSeek系列的整体框架:

1 模型架构设计
基本参数
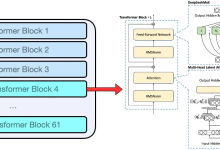
- DeepSeek-R1和DeepSeek-V3采用同样的模型参数,并且设计和DeepSeek-V2类似
- Attention采用多头潜在注意力机制(MLA)
- FFN采用无辅助损失的DeepSeekMoE
- 61层Transformer Layer
- MoE中1个共享专家,256个路由专家,对每个token选择top-8专家

专家混合模型(MoE)[DeepSeek-V2提出, DeepSeek-V3改良]
MoE在每次推理时选择性地激活部分模型参数,在不成比例增加计算成本的情况下,可以扩展模型参数。在DeepSeek-V2中就已经提出了用于FFN层的DeepSeekMoE。
- 动态专家分配:根据token的上下文动态分配合适的专家
- DeepSeek-V2引入辅助损失进行负载均衡,确保token在专家之间的分配更加均衡。DeepSeek-V3和DeepSeek-R1进一步采用用auxiliary-loss-free load balancing实现负载均衡,引入一个expert bias,这个bias只影响专家路由,而不影响任何梯度。动态调整bias,专家overloaded则降低bias,专家unoverloaded则增大bias。简单来说就是用加法高效地对gating score进行re-weight的过程
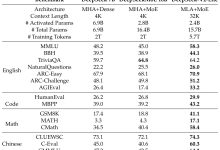
- DeepSeek-R1和DeepSeek-V3一致,总参数量671B,通过MoE对单个token的激活参数量仅37B (~5.5%)。MoE中有1个shared expert+256个routed expert,每次只激活的8个exert。
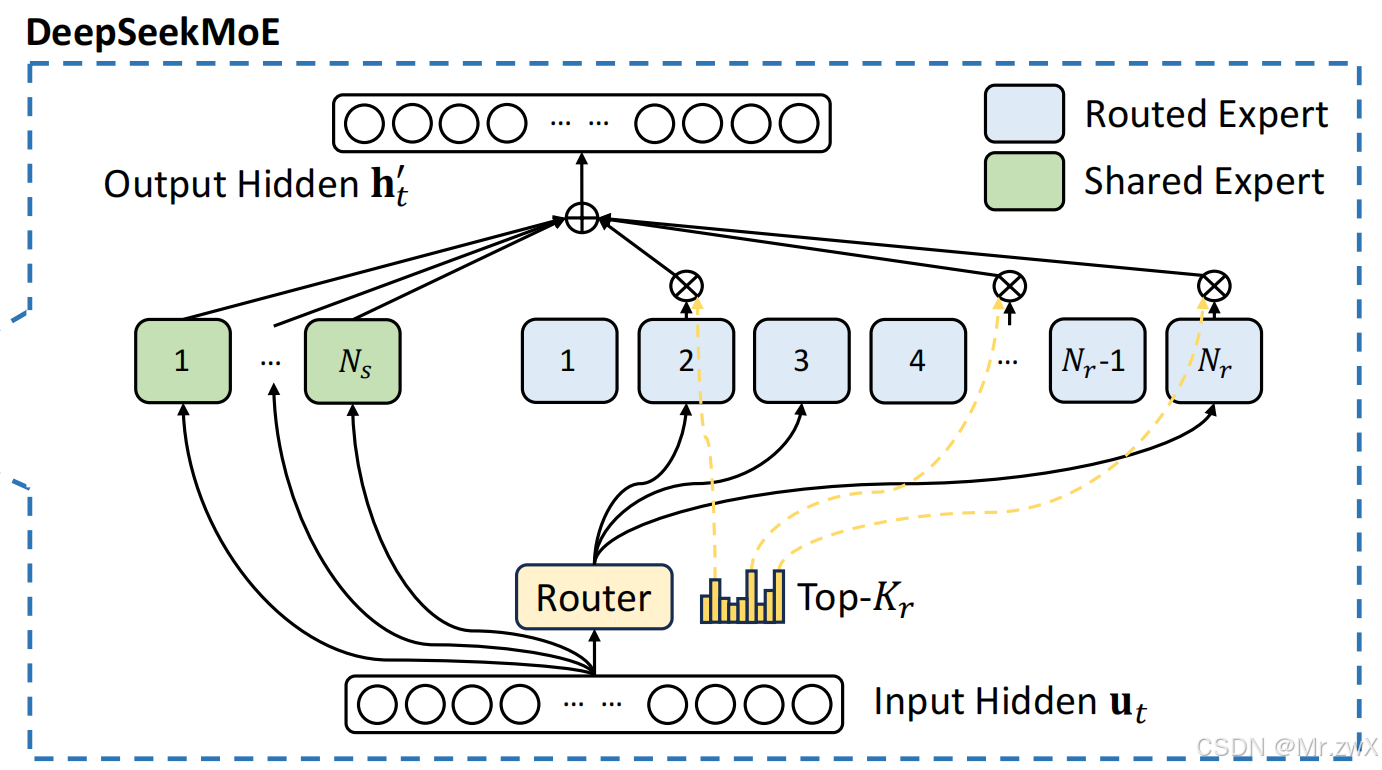 Auxiliary-Loss-Free Load Balancing [DeepSeek-V3提出] 和DeepSeek-V3一样,DeepSeek-R1采用了细粒度的MoE,一些expert作为共享expert,另一些expert作为routed expert进行动态激活。对于第t个token u t u_t ut,下面是MoE计算的过程:
Auxiliary-Loss-Free Load Balancing [DeepSeek-V3提出] 和DeepSeek-V3一样,DeepSeek-R1采用了细粒度的MoE,一些expert作为共享expert,另一些expert作为routed expert进行动态激活。对于第t个token u t u_t ut,下面是MoE计算的过程:
 以前基于auxiliary loss的方法需要修改loss function,当auxiliary loss很大时会影响模型性能。那么Auxiliary-Loss-Free则是在gating value g g g的基础上,额外加上了bias来实现负载均衡:
以前基于auxiliary loss的方法需要修改loss function,当auxiliary loss很大时会影响模型性能。那么Auxiliary-Loss-Free则是在gating value g g g的基础上,额外加上了bias来实现负载均衡:
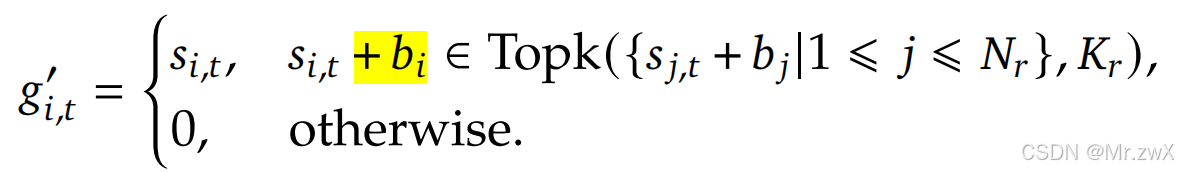 注意bias只影响专家路由,而不影响任何梯度。专家overloaded则降低bias,专家unoverloaded则增大bias。调整的速度由超参数 γ \\gamma γ控制,这个和反向传播的梯度更新过程类似。
注意bias只影响专家路由,而不影响任何梯度。专家overloaded则降低bias,专家unoverloaded则增大bias。调整的速度由超参数 γ \\gamma γ控制,这个和反向传播的梯度更新过程类似。
下图是该方法的出处:Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts文章所提出的负载均衡策略: 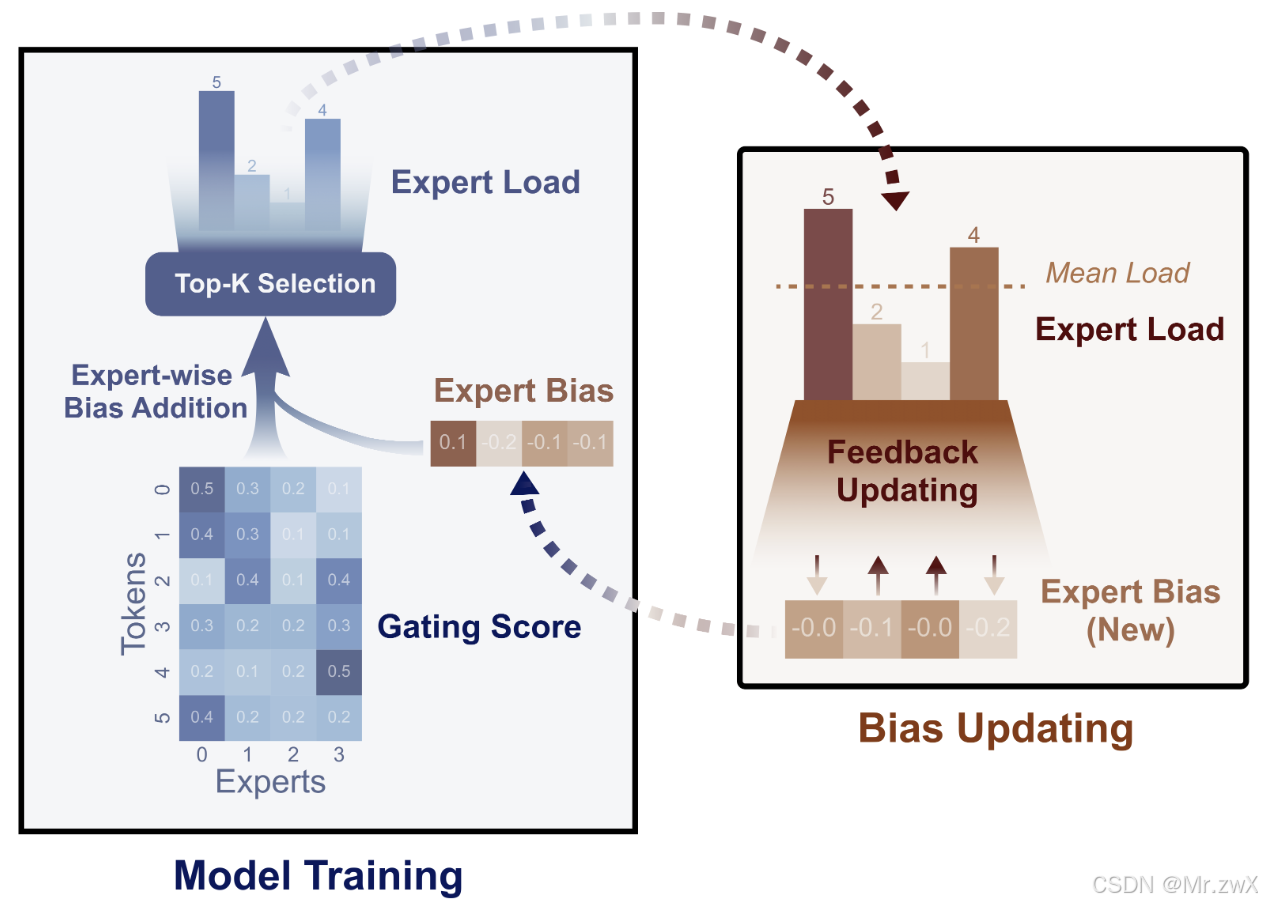 和DeepSeek-V2一样,DeepSeek-V3和DeepSeek-R1都采用了限制设备数量的MoE,并且不会再训练时做token dropping了。
和DeepSeek-V2一样,DeepSeek-V3和DeepSeek-R1都采用了限制设备数量的MoE,并且不会再训练时做token dropping了。
多头潜在注意力(MLA)[DeepSeek-V2提出]
MLA通过将QKV矩阵投影到低维潜在空间,显著降低计算和内存成本。DeepSeek-V2中就提出了用MLA来替代传统的多头自注意力。
MLA和其他注意力的对比如下,KV cache以一个更低的维度去存储和计算。  K和V的联合压缩如下:
K和V的联合压缩如下: 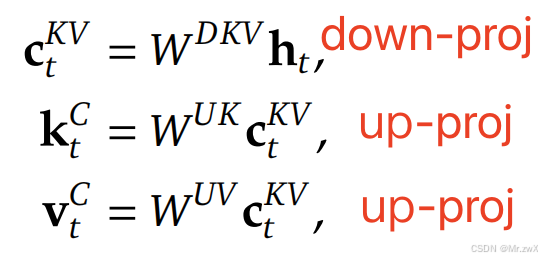
真正推理时,cache的就是低维的 c t K V c_t^{KV} ctKV,并且down-proj和up-proj矩阵可以分别被吸收进 W Q W^Q W




评论前必须登录!
注册