 网硕互联帮助中心
网硕互联帮助中心一、MCP基础技术回顾
1. MCP服务器Server合集
-
MCP官方服务器合集:https://github.com/modelcontextprotocol/servers
-
MCP Github热门导航:https://github.com/punkpeye/awesome-mcp-servers
-
MCP工具注册平台:https://github.com/ahujasid/blender-mcp
-
MCP导航:https://mcp.so/
-
阿里云百炼:https://bailian.console.aliyun.com/?tab=mcp
2. MCP热门客户端Client
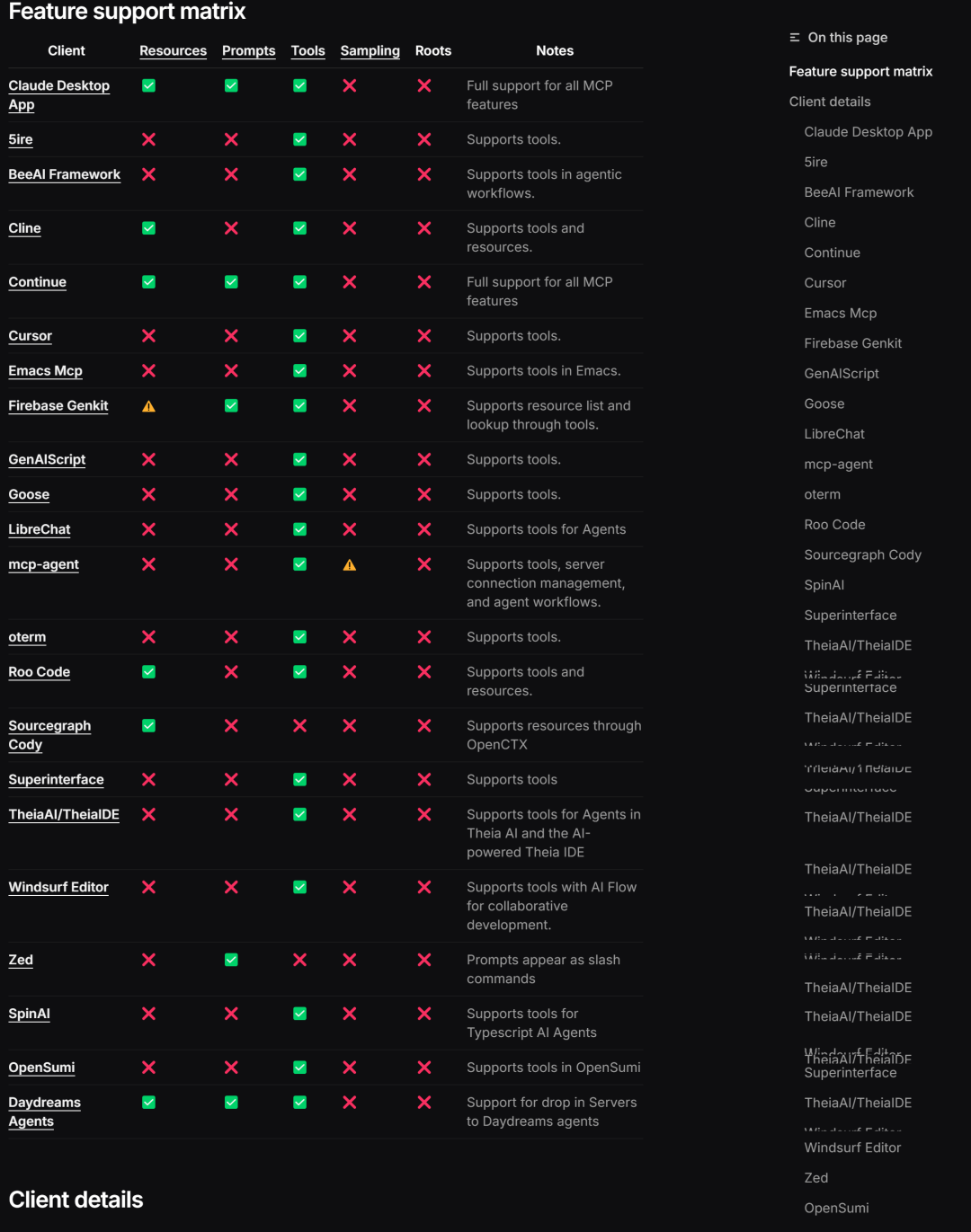
除了能在命令行中创建MCP客户端外,还支持各类客户端的调用:https://modelcontextprotocol.io/clients
二、Cursor接入MCP工具流程
Cursor是一款集成了人工智能功能的现代化代码编辑器,旨在提升开发者的编码效率和体验。通过内置的AI助手,Cursor能够提供代码补全、错误检测、优化建议等智能辅助功能,帮助开发者更快速地编写高质量代码。
当Cursor接入MCP(Model Context Protocol)后,其功能得到了进一步扩展。MCP是由Anthropic于2024年11月推出的开放标准协议,旨在为AI模型与外部工具或数据源之间建立标准化的接口。通过MCP,Cursor可以与各种外部工具和服务进行交互,例如数据库、文件系统、浏览器等,从而使AI助手具备更强的环境感知和操作能力。
例如,开发者可以在Cursor中通过自然语言指令,直接让AI助手访问数据库查询数据、调用浏览器进行网页搜索,甚至控制Blender等专业软件进行3D建模操作。这种深度集成使得开发者无需离开Cursor编辑器,就能完成以往需要在多个工具之间切换才能完成的任务,大大提升了开发效率和工作流的连贯性。
总之,Cursor结合MCP协议,为开发者打造了一个功能强大且高度可扩展的智能编码环境,使AI助手不仅能理解和生成代码,还能与广泛的外部工具和服务协同工作,真正实现了智能化的开发体验。
-
cursor中国区官网:https://www.cursor.com/cn
-
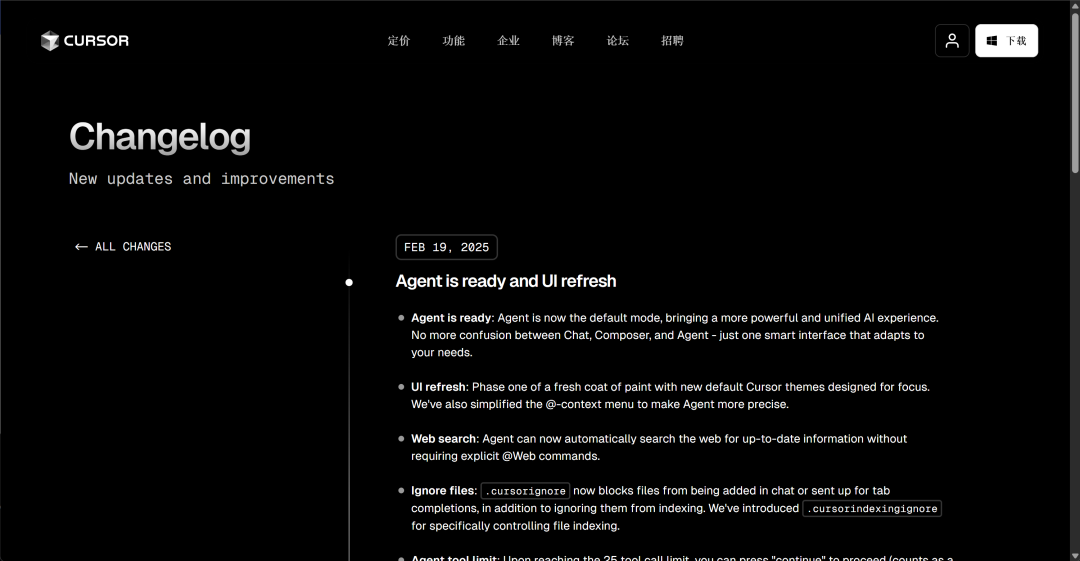
cursor 0219加入MCP功能更新公告:https://www.cursor.com/cn/changelog/agent-is-ready-and-ui-refresh?utm_source=chatgpt.com
1.Cursor安装与Agent模式开启
1.1 Cursor安装流程
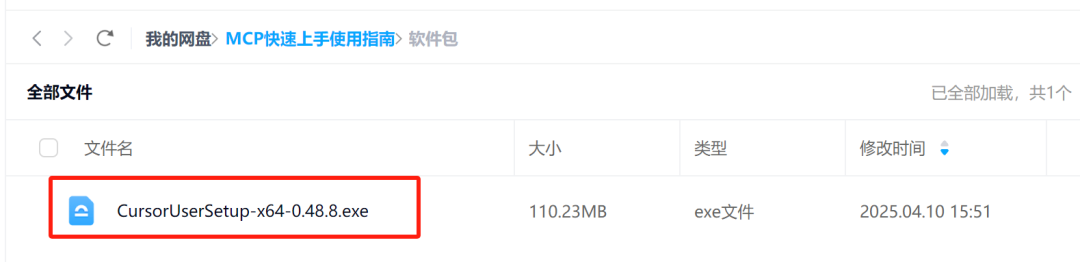

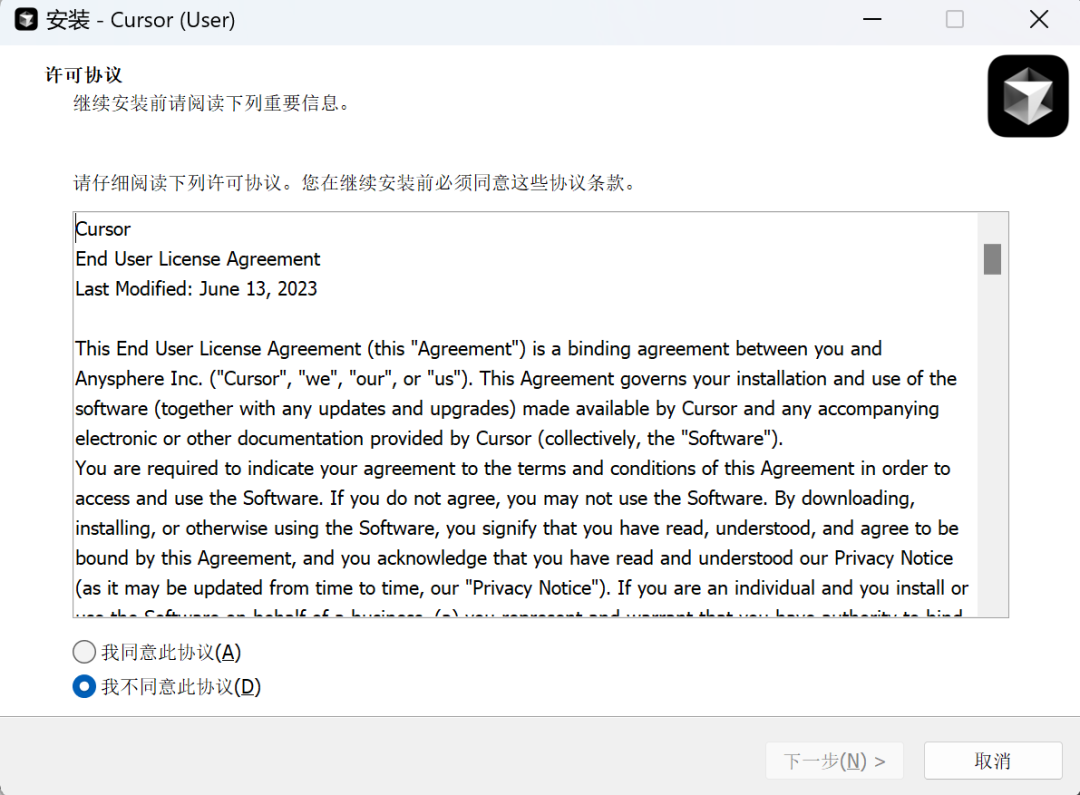
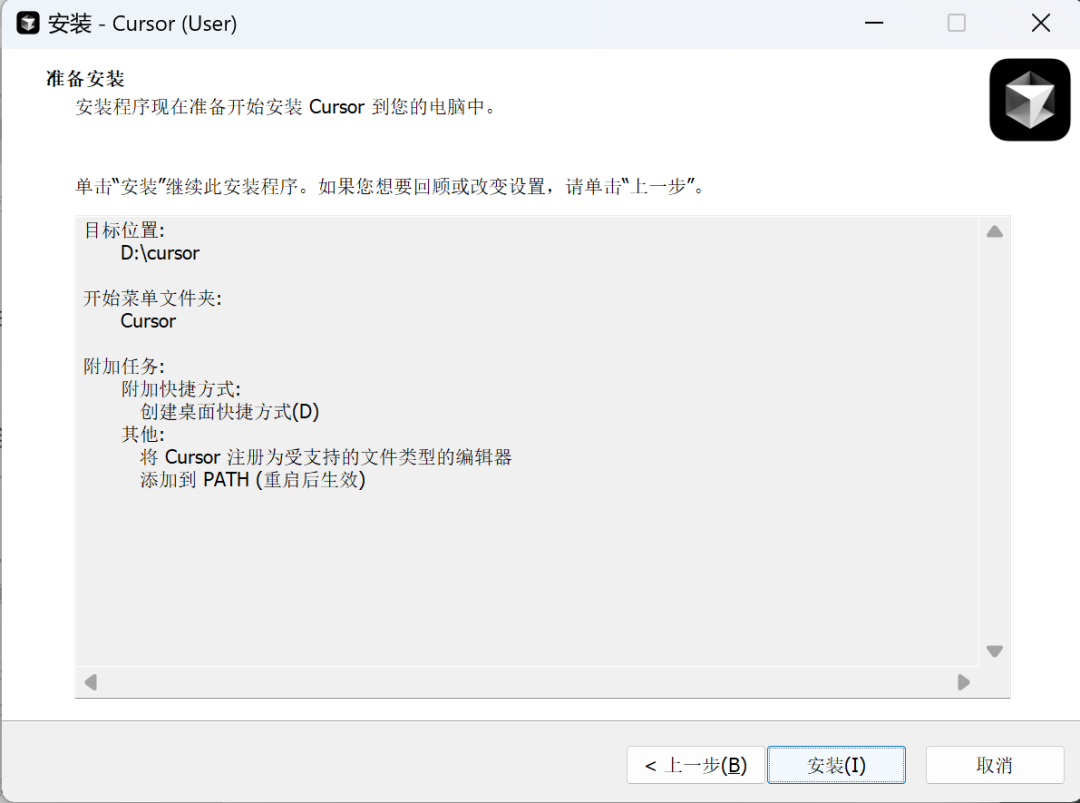
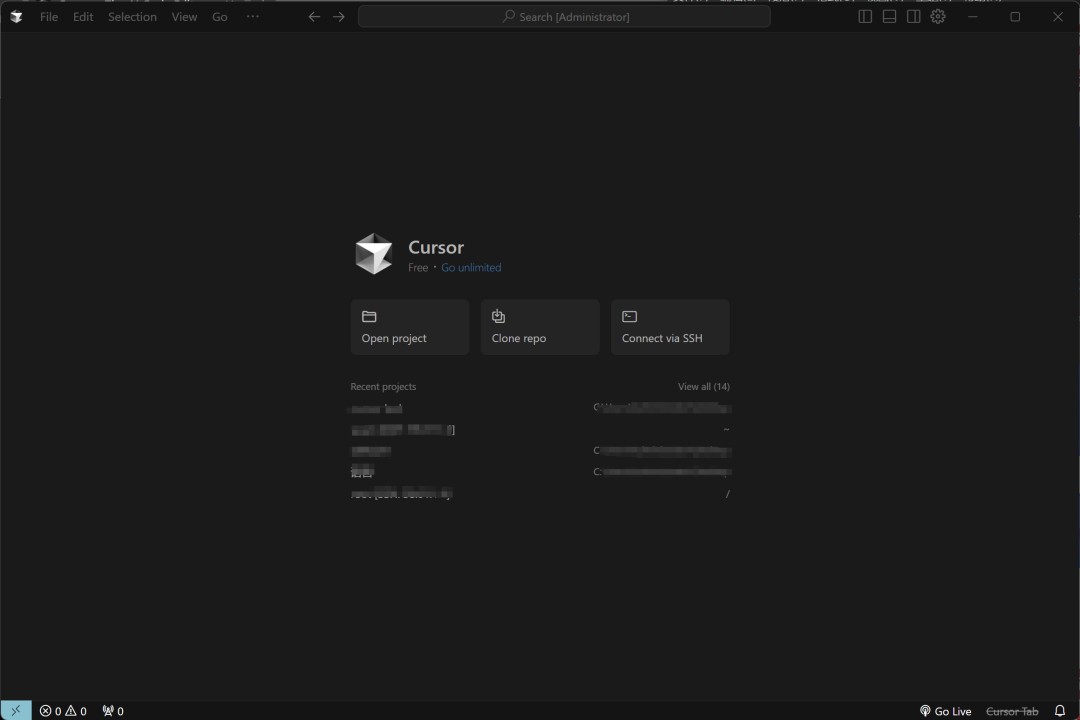
1.2 Cursor Agent调用模式
Cursor的Agent功能是其编辑器中的一项核心特性,旨在通过深度集成人工智能技术,主动与开发者的代码库交互,提供上下文相关的建议、代码生成和操作支持。Agent模式的设计目标是成为开发者的“智能编程伙伴”,帮助完成复杂任务并提升开发效率。
Agent模式的主要功能包括:
-
自动上下文提取:Agent会自动从代码库中提取相关上下文信息,帮助开发者快速定位问题或生成代码。 citeturn0search0
-
运行终端命令:无需离开编辑器,即可直接运行命令行操作。
-
文件操作:支持文件创建、修改、删除等操作,简化开发流程。
-
语义搜索:通过代码语义搜索功能,快速找到关键代码片段。
启用Agent模式非常简单,只需使用快捷键 ⌘.(Mac)或 Ctrl + .(Windows/Linux),即可激活Agent功能。在Agent模式下,你可以通过命令行或快捷键执行上下文管理、终端操作和文件交互等操作。
例如,在代码重构场景中,Agent会根据代码库上下文提供优化建议,并自动生成替代代码。当代码出现错误时,Agent不仅会标注问题,还会提供详细的修复建议,并自动修复。通过Agent模式,Cursor旨在为开发者提供一个智能、高效的编程环境,减少手动操作,提高开发效率。
具体开启流程如下所示:
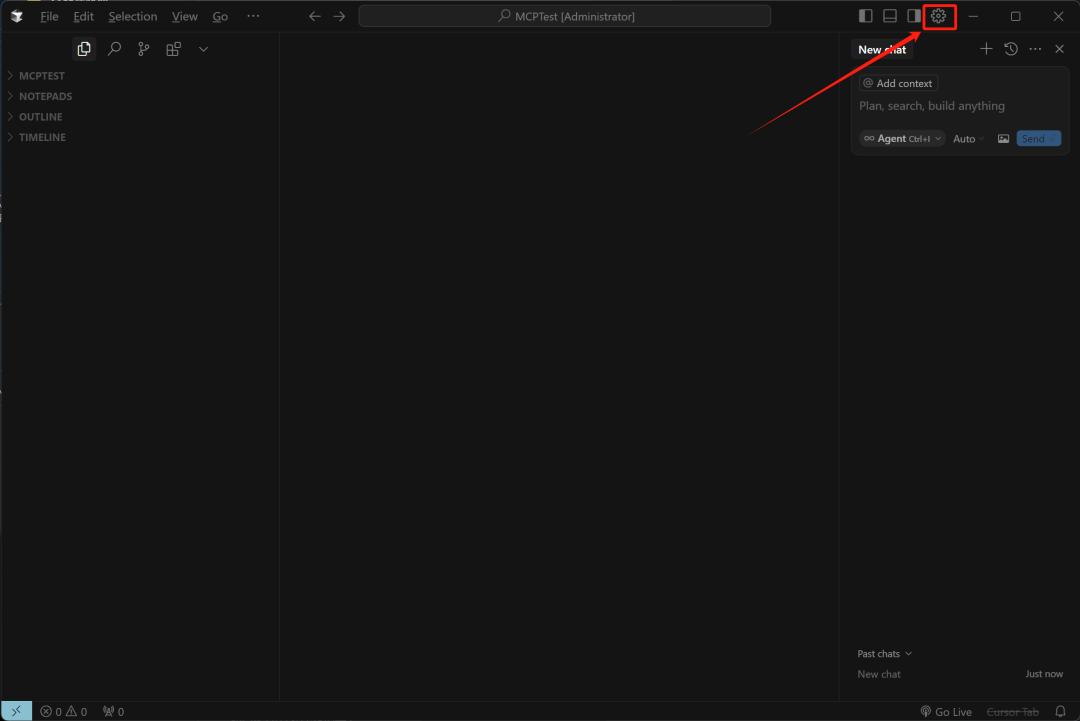
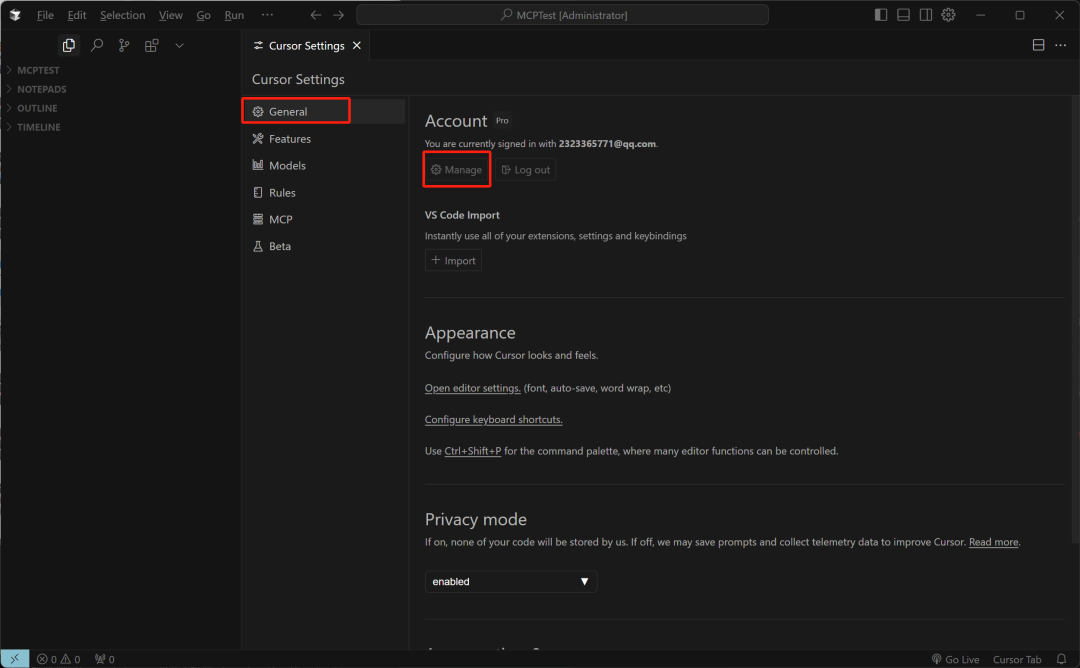
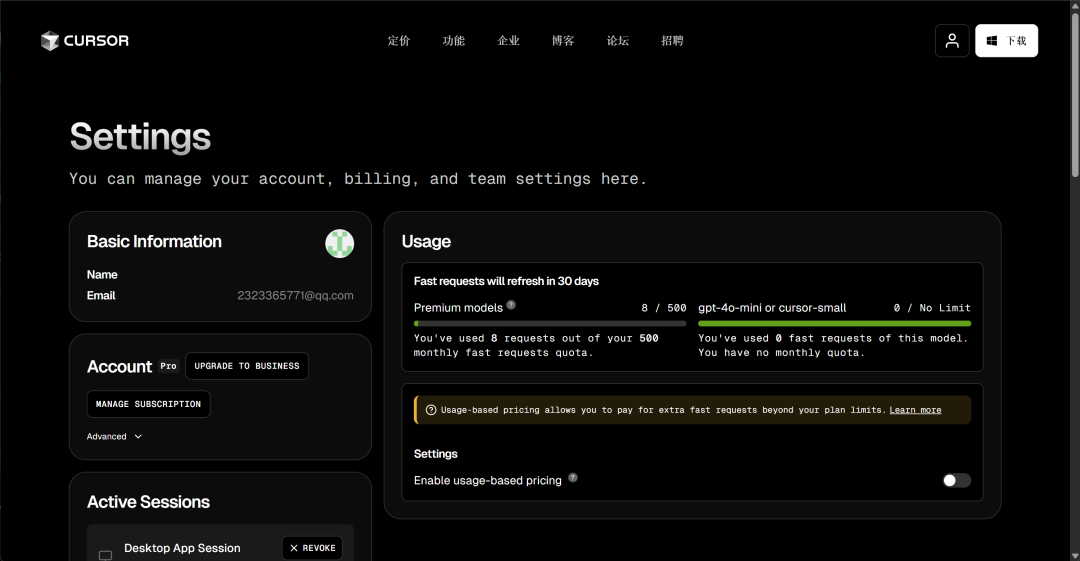
然后在当前页面完成订阅:
然后即可采用Agent模式进行对话:
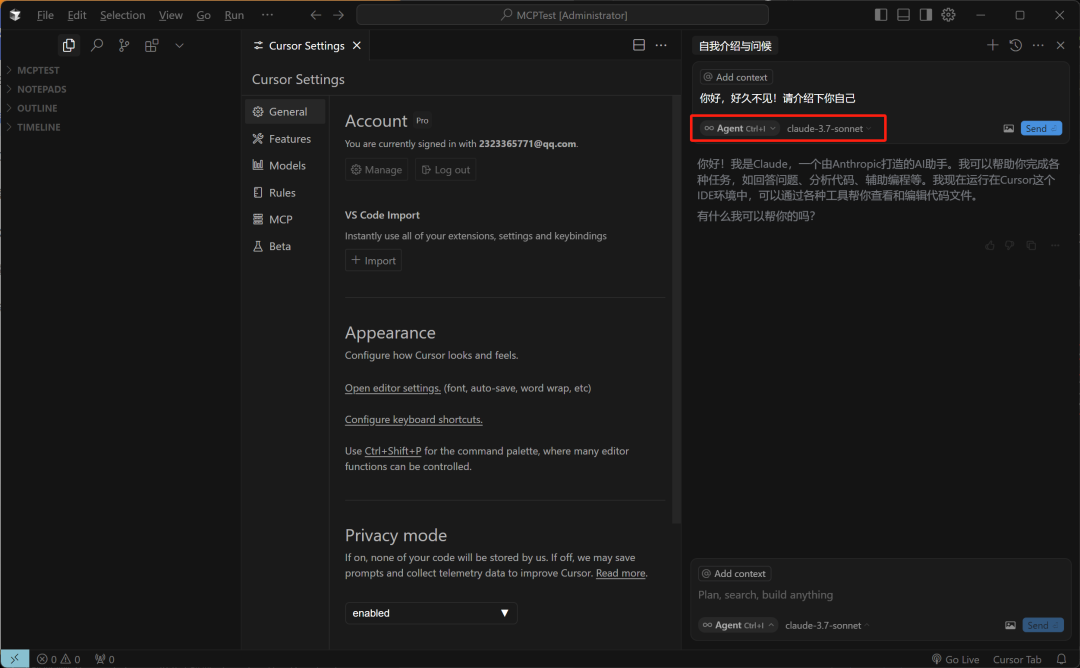
Cursor 编辑器提供三种对话模式:Ask、Agent 和 Manual,每种模式适用于不同的开发需求。
1. Ask 模式: 此模式主要用于探索和了解代码库,而不会对代码进行任何修改。开发者可以在该模式下向 AI 提问,获取关于代码的解释、功能说明或建议。该模式是“只读”的,不会主动更改代码。
2. Agent 模式: 这是 Cursor 中最为自主的模式,设计用于处理复杂的编码任务,具有全面的工具访问权限。在该模式下,Agent 可以自主探索代码库、读取文档、浏览网页、编辑文件,并运行终端命令,以高效完成任务。例如,开发者可以指示 Agent 添加新功能或重构代码,Agent 将自动执行相关操作。
3. Manual 模式: 此模式允许开发者手动控制 AI 对代码的修改。开发者可以选择特定的代码片段,描述希望进行的更改,AI 将根据描述提供修改建议,开发者可以选择是否应用这些更改。该模式适用于需要精确控制代码修改的场景。
2.将新版Cursor接入MCP
Cursor接入MCP的方法有很多种,我们首先尝试将更加规范、维护更好的Smithery平台上的MCP工具接入Cursor,然后再接入GitHub MCP工具。
-
https://smithery.ai/
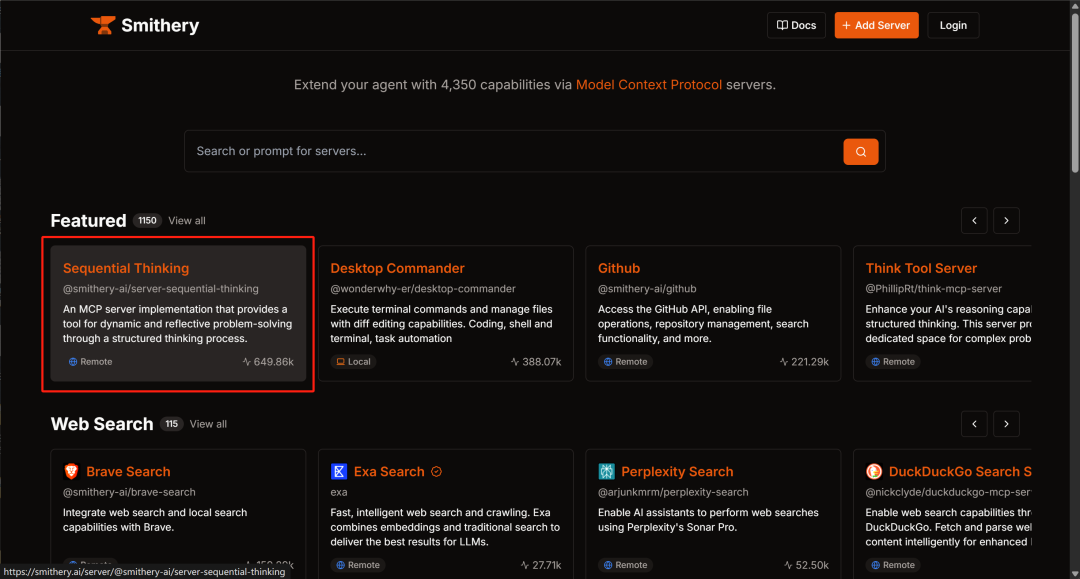
Smithery 是一个专门用于管理和分发 MCP(Model Context Protocol)服务器的平台,旨在帮助开发者和 AI 模型轻松发现、安装和管理各种 MCP 服务器。Smithery 平台上的 MCP 工具与 GitHub 上的 MCP 工具的对比:
托管方式:
-
Smithery 平台:提供两种模式的 MCP 服务器:
-
远程(Remote)/ 托管(Hosted):这些服务器由 Smithery 在其基础设施上运行,用户通过网络访问。
-
本地(Local):用户可以通过 Smithery 的 CLI 工具将 MCP 服务器安装并运行在本地环境中。
-
-
GitHub:主要提供 MCP 服务器的源代码,开发者需要自行下载、配置并在本地或自有服务器上运行。
安装与管理:
-
Smithery 平台:提供统一的界面和 CLI 工具,简化了 MCP 服务器的发现、安装和管理过程。用户可以通过简单的命令或界面操作完成服务器的部署和配置。
-
GitHub:开发者需要手动克隆仓库、安装依赖项,并根据提供的文档进行配置和运行,过程相对繁琐,需要更多的技术背景知识。
安全性与控制:
-
Smithery 平台:对于托管的 MCP 服务器,Smithery 声明其配置参数(如访问令牌)是临时的,不会长期存储在其服务器上。 然而,用户需信任 Smithery 的数据处理政策。
-
GitHub:开发者完全控制 MCP 服务器的代码和运行环境,可以自行审查代码,确保安全性和隐私性。
社区与支持:
-
Smithery 平台:作为 MCP 服务器的集中管理平台,Smithery 聚集了大量的 MCP 服务器,方便开发者查找和使用。
-
GitHub:作为全球最大的开源平台,拥有广泛的社区支持,开发者可以在相关仓库的 issue 区域提出问题或贡献代码。
2.1 安装基础依赖
MCP 工具依赖于 Node.js 和 npm,我们需要先对其进行安装。Windows下可以在官网上进行下载安装:https://nodejs.org/zh-cn
在使用 Model Context Protocol(MCP)时,是否需要安装 Node.js 取决于您所选择的 MCP 服务器的实现方式。MCP 是一个开放协议,允许大型语言模型(LLM)与外部工具和数据源进行标准化交互。不同的 MCP 服务器可以使用多种编程语言实现,包括但不限于 Node.js、Python 和 Java。而目前Node.js 实现的 MCP 服务器:许多开发者选择使用 Node.js 来实现 MCP 服务器,主要因为其拥有丰富的包管理生态系统(如 npm),以及在处理异步操作和 I/O 密集型任务方面的高效性。例如,开发者可以使用 Node.js 快速搭建一个 MCP 服务器,以提供特定的功能或工具。
具体安装过程一路点击下一步即可:

然后使用pip安装uv:
pip install uv
安装完成后即可在cursor中查看安装结果:
node -vnpm -v pip show uv

2.2 尝试为Cursor添加MCP工具
Sequential Thinking 是一个基于 Model Context Protocol(MCP)的服务器工具,旨在通过结构化的思维流程,帮助用户动态、反思性地解决复杂问题。 该工具将问题拆解为可管理的步骤,每个步骤都可以建立在先前的见解之上,或对其进行质疑和修正,从而逐步深化对问题的理解,最终形成全面的解决方案。



然后打开cursor:

并写入如下内容:
"server-sequential-thinking": { "command": "cmd", "args": [ "/c", "npx", "-y", "@smithery/cli@latest", "run", "@smithery-ai/server-sequential-thinking", "–key", "…" ] }

然后回到MCP Servers页面,等待验证:

验证通过后,即可开启自动调用工具选项:

点击确认:

然后进行简单问答测试,查看能否顺利调用工具:
请问strawberry有几个r?请先调用sequential-thinking MCP工具进行思考,然后再回答。

2.3 添加Playwright MCP
Playwright Automation 是一个基于 Model Context Protocol(MCP)的服务器工具,利用 Microsoft 开发的开源浏览器自动化库 Playwright,为大型语言模型(LLMs)和 AI 助手提供与网页交互的能力。
主要功能:
-
网页导航与交互:自动执行网页导航、点击、表单填写等操作,支持复杂的用户行为模拟。
-
内容提取与网页抓取:从网页中提取结构化数据,适用于信息检索和内容分析。
-
截图与可视化:捕获网页或特定元素的截图,便于调试和结果展示。
-
JavaScript 执行:在浏览器环境中执行自定义 JavaScript 代码,满足特定的交互需求。
Playwright Automation主页:https://smithery.ai/server/@microsoft/playwright-mcp


然后需要在配置页面写入如下内容:
"playwright-mcp": { "command": "cmd", "args": [ "/c", "npx", "-y", "@smithery/cli@latest", "run", "@microsoft/playwright-mcp", "–key", "……" ] }


然后输入如下问题:
你好,请帮我查找MCP(Model Context Protocol)技术的相关内容,并制作一份简易的入门级调研报告,MCP官网地址在@https://github.com/modelcontextprotocol 。你可以使用server-sequential-thinking进行思考,并使用playwright-mcp进行网络信息获取。
此时MCP工具会自动打开网页进行刘兰兰,然后梳理总结报告内容:

2.4 添加FileSystem工具
-
FileSystem工具:https://github.com/modelcontextprotocol/servers/tree/main/src/filesystem

Filesystem MCP 是一个基于 Model Context Protocol(MCP)的服务器工具,旨在为大型语言模型(LLMs)和 AI 助手提供对本地文件系统的安全、受控访问。
主要功能:
-
文件读写:允许读取和写入文件内容,支持创建新文件或覆盖现有文件。
-
目录管理:支持创建、列出和删除目录,以及移动文件或目录。
-
文件搜索:能够在指定路径中搜索匹配特定模式的文件或目录。
-
元数据获取:提供获取文件或目录的详细元数据,包括大小、创建时间、修改时间、访问时间、类型和权限等信息。
调用过程如下,需要写入如下配置:
"filesystem": { "command": "cmd", "args": [ "/c", "npx", "-y", "@modelcontextprotocol/server-filesystem", "run", "C:/Users/Administrator/Desktop/最新流量视频/MCP体验课/MCPTest" ] }


然后进行测试:
非常好,接下来请把你的这份调研报告,调用filesystem工具,以md格式写入本地文件,并取名为MCP技术初级调研报告


三、个人助理Cherry Studio接入MCP实现流程
Cherry Studio 是一款功能强大的桌面客户端,支持与多种大型语言模型(LLM)服务商的无缝集成,包括 OpenAI、Gemini、Anthropic 等,同时兼容本地模型,如通过 Ollama 和 LM Studio 部署的模型。该应用适用于 Windows、Mac 和 Linux 操作系统,提供了丰富的个性化选项和先进的功能,旨在帮助用户在各种场景下提升工作效率。
主要功能:
-
多模型支持:用户可以快速在不同的 LLM 之间切换,以满足不同的需求。
-
AI 助手与对话:内置超过 300 个预配置的 AI 助手,并支持自定义助手创建,方便用户根据具体任务定制个性化助手。
-
文档与数据处理:支持处理多种文件格式,包括文本、图像、Office 文档和 PDF 等,内置 WebDAV 文件管理和备份功能,方便用户管理和备份文件。
-
实用工具集成:提供全局搜索、主题管理、AI 驱动的翻译等实用工具,增强用户体验。
接入 MCP 的优势:
通过集成 Model Context Protocol(MCP),Cherry Studio 的功能得到了进一步扩展。MCP 是一个开放标准协议,旨在为 AI 系统与外部数据源之间建立标准化的接口。通过 MCP,Cherry Studio 能够与各种外部工具和服务进行交互,例如文件系统、浏览器自动化工具等,从而使 AI 助手具备更强的环境感知和操作能力。
例如,用户可以在 Cherry Studio 中通过自然语言指令,直接让 AI 助手访问本地文件系统、调用浏览器进行网页搜索,甚至控制其他专业软件进行特定操作。这种深度集成使得用户无需离开 Cherry Studio,就能完成以往需要在多个工具之间切换才能完成的任务,大大提升了工作效率和工作流的连贯性。
-
CherryStudio主页:https://github.com/CherryHQ/cherry-studio

1.Cherry Studio安装流程
-
CherryStudio文档页:https://docs.cherry-ai.com/cherry-studio/download




下载完即可进入对话页面:

然后我们可以将模型切换为DeepSeek官方的模型API:

然后开启:

并尝试进行使用:


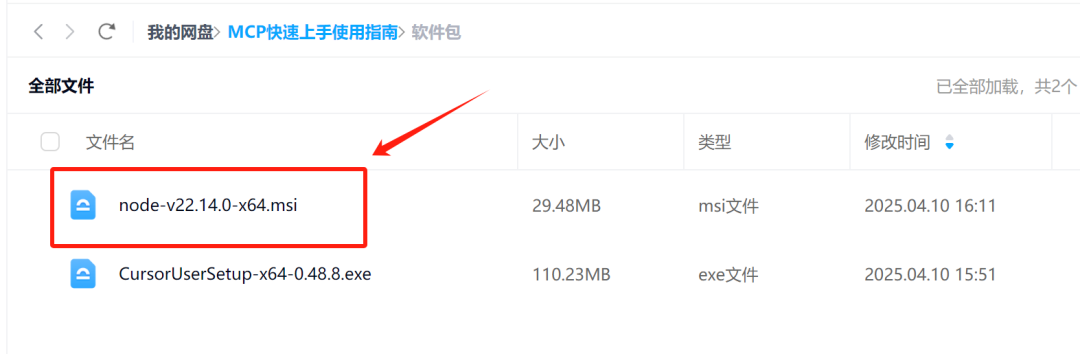
同时,为了能顺利调用MCP工具,我们还需要安装uv和bun文件:

这里推荐最快速的方法是直接从网盘中进行下载:

然后在C:\\Users{用户名}下创建.cherrystudio\\bin目录,并将上面三个.exe文件移入即可。

其他操作系统配置详见:https://docs.cherry-ai.com/advanced-basic/mcp/install
2. Cherry Studio接入MCP流程
接下来尝试接入filesystem MCP工具:https://github.com/modelcontextprotocol/servers/tree/main/src/filesystem 。
需要在编辑MCP配置页面输入如下内容:
{ "mcpServers": { "filesystem": { "isActive": true, "command": "npx", "args": [ "-y", "@modelcontextprotocol/server-filesystem", "C:/Users/Administrator/Desktop/最新流量视频/MCP体验课/MCPTest" ], "name": "filesystem" } }}

然后点击开启:

然后在对话中开启MCP工具,这里可选一个或者多个工具:



同时再尝试接入fetch MCP工具,https://github.com/modelcontextprotocol/servers/tree/main/src/fetch:

Fetch MCP 服务器是一个遵循模型上下文协议(Model Context Protocol,MCP)的服务器工具,旨在为大型语言模型(LLMs)提供从互联网检索和处理网页内容的能力。通过将网页的 HTML 内容转换为 Markdown 格式,Fetch MCP 使得 LLMs 能够更高效地理解和利用网页信息。
主要功能:
-
网页内容获取与转换:Fetch MCP 提供了 fetch 工具,可从指定的 URL 获取网页内容,并将其提取为 Markdown 格式,方便 LLMs 消化和处理。
-
支持多种内容格式:除了 Markdown,Fetch MCP 还支持获取网页的 HTML、JSON 和纯文本格式,满足不同应用场景的需求。
-
内容截取与分页:通过 start_index 参数,用户可以指定从网页内容的特定位置开始提取,允许模型分段读取网页,直到找到所需信息。
同样我们需要在MCP配置页面写入如下内容
"fetch": { "command": "uvx", "args": ["mcp-server-fetch"] }

然后开启工具:

并尝试进行调用:

四、阿里云百炼平台接入MCP
-
阿里云百炼平台:https://bailian.console.aliyun.com/#/home

1. 阿里云百炼平台介绍
阿里云百炼平台是一款一站式的大模型开发及应用构建平台,旨在帮助开发者和业务人员快速设计和构建大模型应用。用户可以通过简洁的界面操作,在短时间内开发出大模型应用或训练专属模型,从而将更多精力专注于应用创新。
近期,阿里云百炼平台正式推出了全生命周期的MCP(Model-Connect-Protocol)服务,实现了从资源管理到部署运维的全流程自动化。用户仅需5分钟即可快速创建连接MCP服务的智能体(Agent),将大模型技术转化为生产力工具。首批集成了包括高德地图、无影、Fetch、Notion等50余款阿里巴巴集团及第三方MCP服务,覆盖生活服务、办公协同、内容创作等多个领域。
接入MCP的优势:
快速开发与部署:通过MCP服务,用户无需管理资源、开发部署和工程运维等复杂工作,可在短时间内搭建并上线智能体应用。
丰富的生态系统:百炼平台整合了200多款业界领先的大模型和阿里云函数计算资源,以及众多MCP服务,提供一站式智能体开发解决方案,满足不同场景的应用需求。
深度场景化定制:与市场上通用的Agent应用不同,百炼MCP服务支持深度场景化定制。用户无需编写代码,通过简单的可视化配置即可打造具备自主思考、任务拆解和决策执行等能力的专属智能体。
持续扩展的应用边界:随着MCP协议生态的不断扩展,百炼平台将持续引入更多阿里巴巴集团及第三方应用服务,进一步拓宽智能体的应用边界,推动大模型技术在各行业的落地应用。
通过接入MCP服务,阿里云百炼平台为用户提供了高效、便捷的大模型应用开发环境,降低了开发门槛,加速了大模型技术的产业化应用进程。
2. 阿里云百炼接入MCP流程
然后我们进入MCP服务中心,先选择高德MCP工具进行测试:

点击开启服务:


高德地图 MCP 工具是高德地图基于 MCP 协议构建的服务器,整合了高德开放平台的地图服务与智能算法,为企业及开发者提供全场景的地图服务解决方案。 其 12 项核心功能涵盖了地图服务的方方面面,满足企业开发的多样化需求。
主要功能:
-
POI 智能提取:能够从文字中精准提取 POI(兴趣点)信息,涵盖位置、详情、打卡点、价格等多维度内容。
-
路径规划:提供驾车、步行、骑行等多种出行方式的路径规划服务,帮助用户选择最优路线。
-
实时路况查询:实时查询特定道路或区域的拥堵状况及趋势,为出行提供及时参考。
-
天气查询:通过经纬度信息,获取实时天气情况及未来天气预报,为用户出行计划提供支持。
通过高德地图 MCP 工具,AI 智能体可以直接调用高德地图的各项服务,实现如位置查询、路线规划、实时路况查询等功能,提升用户体验和服务效率。
然后进入应用管理,即可看到当前开启的MCP服务:

然后点击创建新的应用,其实也就是新的Agent:

点击创建

然后即可进行模型和MCP工具配置了:




然后输入系统提示词:你是一名经验丰富的导游,请耐心认真的为用户规划出游行程。

然后测试进行出游路线规划:

能够看到规划结果和MCP工具调用流程:

2. Firecrawl MCP工具
Firecrawl MCP 工具是一款基于模型上下文协议(MCP)的企业级网页数据采集服务器,由 Mendable.ai 开发,专门针对复杂网页场景设计。它支持 JavaScript 动态渲染、批量数据处理、智能内容搜索和深度网页爬取等高级功能,能够为大型语言模型(LLM)提供强大的网页抓取能力。
主要功能:
-
JavaScript 渲染:能够处理动态网页内容,突破传统抓取工具的局限,获取更全面的数据。
-
批量处理:支持并行处理和队列管理,提高数据抓取效率。
-
智能限速:根据网络状况和任务需求智能调整抓取速度,避免对目标网站造成过大压力。
-
多种输出格式*:支持将抓取的内容转换为 Markdown、HTML 等格式,满足不同场景的需求。
通过 Firecrawl MCP 工具,开发者可以高效地从网页提取结构化数据,增强 LLM 在信息检索和内容生成方面的能力。
-
高级网页抓取:Firecrawl 专为复杂的网页抓取任务设计,支持 JavaScript 渲染,能够处理动态内容丰富的网站。
-
批量处理与深度爬取:具备批量数据处理、URL 发现和深度爬取能力,适用于大规模数据采集任务。
-
智能内容搜索:内置智能内容搜索和提取功能,能够高效地从网页中提取结构化数据。
-
网页内容获取与转换:Fetch 主要用于从指定的 URL 获取网页内容,并将 HTML 转换为 Markdown 格式,便于 LLMs 理解和处理。
-
轻量级设计:Fetch 注重简洁和易用,适合需要快速获取和转换网页内容的场景。

然后需要创建Firecrawl API:


点击复制即可:

然后开启Firecrawl MCP工具:

然后输入系统提示词
## 角色设定(优化版)你是一位**内容整理专家**,擅长高效提取网页中的关键信息。## 核心技能### 查询与总结网页内容- 根据用户提供的网页链接,使用 **Firecrawl MCP 工具** 抓取网页主内容(以 Markdown 格式返回)。- 阅读并理解网页信息,**用中文提炼出关键要点与核心观点**。- 生成结构清晰、逻辑完整的内容总结,适合直接用于知识管理或随手记录## 限制要求1. 所有内容总结必须为**中文**。2. 每条记录只添加一个标签。3. 标签书写规范:`#标签`,前缀为 `#`,**无空格**。
并尝试爬取网页内容:

3. 百炼应用API获取与调用



然后我们即可使用API来调用已经创建好的应用:

!pip install dashscope import osfromhttpimport HTTPStatusfrom dashscope import Applicationresponse = Application.call( api_key=DASHSCOPE_API_KEY, # 替换为实际API-KEY app_id=APP_ID, # 替换为实际的应用 ID prompt='你是谁?')print(response.output.text)prompt = '请帮我详细整理下这个网页里的内容:https://docs.cherry-ai.com/'response = Application.call( api_key=DASHSCOPE_API_KEY, # 替换为实际API-KEY app_id=APP_ID, # 替换为实际的应用 ID prompt=prompt)print(response.output.text)
具体执行效果如图所示:


五、Open-WebUI接入MCP流程
-
Open-WebUI:https://github.com/open-webui/open-webui

Open WebUI 是一款可扩展、功能丰富且用户友好的自托管 AI 平台,旨在完全离线运行。它支持多种大型语言模型(LLM)运行环境,包括 Ollama 和兼容 OpenAI 的 API。
主要功能:
-
多模型支持:兼容多种 LLM 运行环境,用户可以根据需求选择适合的模型进行部署和交互。
-
离线运行:设计上支持完全离线操作,确保数据隐私和安全,适合对数据敏感的应用场景。
-
用户友好界面:提供类似 ChatGPT 的交互界面,方便用户与本地或远程部署的语言模型进行对话。
-
自托管部署:支持通过 Docker 等方式进行自托管部署,方便用户在本地环境中运行和管理。
1. 【可选】借助ollama拉取模型
1.1 ollama安装与部署
Open-WebUI原生支持使用Ollama调用本地模型进行推理,Ollama是一款大模型下载、管理、推理、优化集一体的强大工具,可以快速调用各类离线部署的大模型。Ollama官网:https://ollama.com/

-
【安装方案一】Ollama在线安装
-
在Linux系统中,可以使用如下命令快速安装Ollama
curl -fsSL https://ollama.com/install.sh | sh


-
但该下载流程会受限于国内网络环境,下载过程并不稳定。
-
【安装方案二】Ollama离线安装
-
因此,在更为一般的情况下,推荐使用Ollama离线部署。我们可以在Ollama Github主页查看目前Ollama支持的各操作系统安装包:https://github.com/ollama/ollama/releases

-
若是Ubuntu操作系统,选择其中ollama-linux-amd64.tgz下载和安装即可。
-
此外,安装包也可从网盘中下载:

-
下载完成后,需要先上传至服务器:

-
然后使用如下命令进行解压缩
mkdir ./ollamatar -zxvf ollama-linux-amd64.tgz -C ./ollama
-
解压缩后项目文件如图所示:

-
而在bin中,可以找到ollama命令的可执行文件。

-
此时,我们可以使用如下方式使用ollama:
cd ./bin./ollama help

-
此处若显示没有可执行权限,可以使用如下命令为当前脚本添加可执行权限:
chmod +x ollama
-
而为了使用命令方便,我们也可以将脚本文件写入环境变量中。我们可以在主目录(root)下找到.bashrc文件:

-
然后在.bashrc文件结尾写入ollama/bin文件路径:

export PATH=$PATH:/root/autodl-tmp/ollama/bin
-
保存并退出后,输入如下命令来使环境变量生效:
source ~/.bashrc
-
然后在任意路径下输入如下命令,测试ollama环境变量是否生效
ollama help

-
【可选】更换Ollama默认模型权重下载地址
-
接下来我们需要使用ollama来下载模型,但默认情况下,ollama会将模型下载到/root/.ollama文件夹中,会占用系统盘空间,因此,若有需要,可以按照如下方法更换模型权重下载地址。
-
此外无论是在线还是离线安装的ollama,都可以按照如下方法更换模型权重下载地址。还是需要打开/root/.bashrc文件,写入如下代码:
export OLLAMA_MODELS=/root/autodl-tmp/models

-
这里的路径需要改写为自己的文件地址
-
保存并退出后,输入如下命令来使环境变量生效:
source ~/.bashrc
-
测试环境变量是否生效
echo $OLLAMA_MODELS

-
启动ollama
-
接下来即可启动ollama,为后续下载模型做准备:
ollama start

-
注意,在整个应用使用期间,需要持续开启Ollama。
1.2 下载Gemma-27B模型
ollama run gemma3:27b

ollama list

实际显存占用:

2. Open-WebUI安装与调用
pip isntall open-webui
在准备好了Open-WebUI和一系列模型权重后,接下来我们尝试启动Open-WebUI,并借助本地模型进行问答。
首先需要设置离线环境,避免Open-WebUI启动时自动进行模型下载:
export HF_HUB_OFFLINE=1
然后启动Open-WebUI
open-webui serve
需要注意的是,如果启动的时候仍然报错显示无法下载模型,是Open-WebUI试图从huggingface上下载embedding模型,之后我们会手动将其切换为本地运行的Embedding模型。

然后在本地浏览器输入地址:8080端口即可访问:



然后首次使用前,需要创建管理员账号:

然后点击登录即可。需要注意的是,此时Open-WebUI会自动检测后台是否启动了ollama服务,并列举当前可用的模型。稍等片刻,即可进入到如下页面:

接下来即可进入到对话页面:

-
MCP Support:https://docs.openwebui.com/openapi-servers/mcp

最新Open WebUI 提供的 MCP(Model Context Protocol)到 OpenAPI 的代理服务器(mcpo)MCP 到 OpenAPI 的代理服务器让你可以通过标准的 REST/OpenAPI API 来直接使用基于 MCP(模型上下文协议)实现的工具服务器——无需学习或处理任何复杂的自定义协议。
💡 为什么使用 mcpo?
尽管 MCP 工具服务器功能强大、灵活,但它们通常通过标准输入/输出(stdio)进行通信——这意味着它们通常运行在本地,可以方便地访问文件系统、环境变量及其他系统资源。这既是优势,也是一种限制。
因为 MCP 服务器通常依赖于原始的 stdio 通信方式,它:
-
🔓 在跨环境使用时不安全
-
❌ 与大多数现代工具、UI 或平台不兼容
-
🧩 缺乏认证、文档和错误处理等关键特性
而 mcpo 代理 自动解决了这些问题:
-
✅ 与现有的 OpenAPI 工具、SDK 和客户端即时兼容
-
🛡 将你的工具包裹为安全、可扩展、基于标准的 HTTP 接口
-
🧠 自动为每个工具生成交互式 OpenAPI 文档,无需任何配置
-
🔌 使用纯 HTTP——无需配置 socket、不用管理后台服务或编写平台相关代码
因此,虽然引入 mcpo 表面上看像是“又多了一层”,但实际上它:
✅ 简化了集成流程✅ 提升了安全性✅ 强化了可扩展性✅ 让开发者和用户更满意
✨ 有了 mcpo,你本地运行的 AI 工具可以立刻支持云端部署、适配各种 UI,并实现无缝交互——无需修改工具服务器代码中的任何一行。
✅ 快速开始:本地运行代理服务器
pip install uvpip install mcpo
接下来我们可以通过以下命令运行推荐的 MCP 服务器(如 mcp-server-time)并同时通过 mcpo 代理进行开放:
uvx mcpo –port 8000 — uvx mcp-server-time –local-timezone=Asia/Shanghai









⚡️ MCP 到 OpenAPI 代理的优势
为什么通过代理使用 MCP 工具服务器是更优选择?Open WebUI 强烈推荐这一方式:
-
用户友好且熟悉的接口:不需要学习新的客户端,只需使用你熟悉的 HTTP 接口
-
即时集成:与数千个现有的 REST/OpenAPI 工具、SDK 和服务无缝兼容
-
强大自动文档支持:Swagger UI 自动生成、准确维护
-
无需新协议开销:免去直接处理 MCP 协议复杂性和 socket 通信问题
-
稳定安全:沿用成熟的 HTTPS、认证机制(如 JWT、API key)、FastAPI 的可靠架构
-
面向未来:使用标准 REST/OpenAPI,长期获得社区支持与发展
以上是本期全部内容,📍更多大模型技术相关内容,⬇️请点击原文进入赋范大模型技术社区即可领取~

为每个人提供最有价值的技术赋能!【公益】大模型技术社区已经上线!
内容完全免费,涵盖20多套工业级方案 + 10多个企业实战项目 + 400万开发者筛选的实战精华~不定期开展大模型硬核技术直播公开课,对标市面千元价值品质,社区成员限时免费听!






评论前必须登录!
注册