 网硕互联帮助中心
网硕互联帮助中心本文来自九天老师的视频,由赋范空间运营进行整理编辑,如果你有任何建议欢迎评论告知哦~
本地部署DeepSeek R1到底需要什么配置?
不同型号的R1模型性能差别有多大?
单卡4090运行R1模型是真的么?
企业百人并发需求,服务器应该如何配置?
我打算购买硬件,如何才能避免踩坑?
本期内容,为你带来全网最详细的DeepSeek R1模型本地部署硬件配置方案。
观前提醒,大模型硬件选配其实并不复杂,但非常繁琐,需要匹配不同场景下各类硬件参数,因此我为大家准备一套速查表,方便大家随时查阅。这套速查表包括:
《大模型推理和训练通用硬件选配表》
《DeepSeek R1各模型硬件需求表》
《DeepSeek R1硬件选配思维导图》

这应该是全网级详细的资料了。
接下来,我们从一个大家最关注的问题开始讨论,那就是本地部署满血版DeepSeek R1模型,到底需要什么配置。
我们假设并发量在100左右,一个稳定的配置是双节点服务器,每个节点的服务器配置是8卡A100 GPU(80G)以及两颗intel 志强8358或6348 CPU,并配置512G内存和5T硬盘,单节点服务器价格在185万上下,双节点服务器总成本约在350万到370万左右。
需要说明一点的是,国内GPU价格水很深,视频中的报价都以一些公开渠道的价格为参考,具体采购价格需根据实际情况确定。
并且,如果是配置A100 GPU,还需要额外将DeepSeek R1模型权重精度由原先的BF8(Brain Floating Point 8)转化为FP16,再进行计算。
|
官方脚本地址:https://github.com/deepseek-ai/DeepSeek-V3/blob/main/inference/fp8_cast_bf16.py |
高效微调相当于是重新训练模型的某一部分参数,往往需要占用更大的显存。

|
Colossal项目官网:https://github.com/hpcaitech/ColossalAI/ |
这样一套服务器,好倒是挺好,但是价格太贵了。有什么方法能够以更低的成本部署DeepSeek R1模型么?有,但需要做些取舍。总的来说,低成本高性能部署方案有三种,分别是:
-
将GPU更换为推理芯片,放弃模型训练功能;
-
将DeepSeek R1模型更换量化模型或蒸馏模型,放弃部分模型性能;
-
采用CPU+GPU混合推理,牺牲部分推理速度。
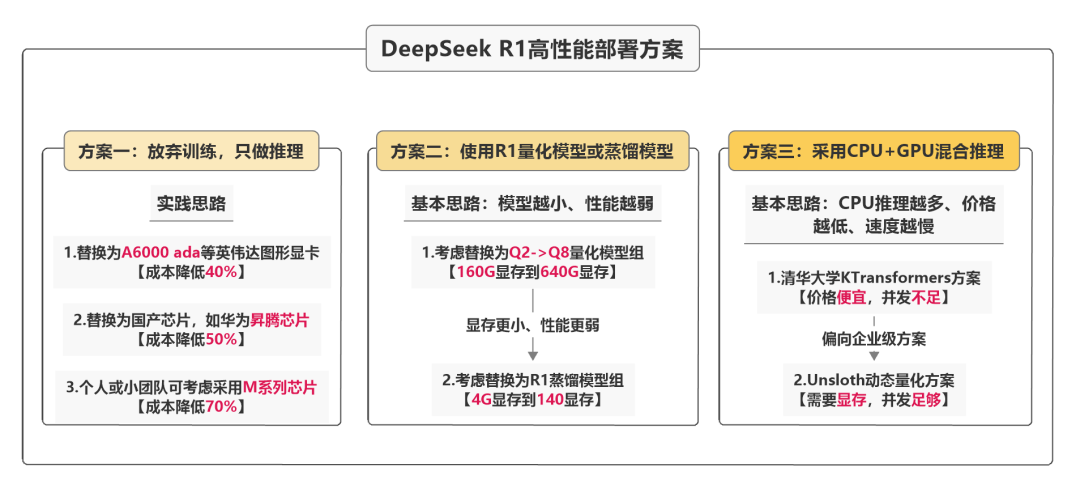
三套方案如图所示,接下来我为大家逐一介绍。
首先,如果我们不需要对模型进行训练或者微调,那么可以考虑将A100替换为一些推理卡、或者国产显卡、甚至是使用Mac M系列芯片,成本将大幅降低,但服务器将不再支持模型训练。
这里我们需要简单做下科普,什么是模型的推理和训练。一般情况下,我们和大模型聊天,或者让模型完成某些任务,这属于模型推理。
而所谓模型训练,指的是通过输入大量的数据,让模型进行学习,从而调整模型的某方面能力,比如说前面谈到的模型微调,就是模型训练的一种形式。
而对于A100这种级别的GPU,是同时具备模型训练和模型推理能力的。但如果实际应用场景不需要进行训练,那确实可以考虑配置只适合进行模型推理的显卡,如英伟达的专业图形显卡,比如RTX6000(ada),48G显存,市场价在5万左右,不到A100(80G)的1/3。
这类显卡原本是为3D渲染所设计,可以进行大模型推理,但训练或者微调性能非常弱。

此外,DeepSeek R1也是全面适配国产芯片的,因此也可以考虑采用华为昇腾芯片,总成本可以降低50%以上,服务器成本可以控制在80万到160万之间。
而如果个人或者小团队使用,并发量在10以内,还可以考虑直接使用苹果的M系列芯片,仅需30万即可采购20台64G MacMini,

借助exo搭建服务器集群,可流畅运行DeepSeek R1模型。

但这些芯片都只能进行模型推理,无法进行模型训练或者微调。这三种芯片方案优劣势对比如图所示。

如果说换芯片是牺牲模型训练能力来换更低的服务器成本,那第二套方案,就是适度牺牲模型性能,来降低硬件成本成本。
其实很多场景下我们并不一定要用到最顶尖的DeepSeek R1 671B模型,有时也可以考虑使用DeepSeek R1量化模型或者蒸馏模型组。这些模型能够在保证性能的情况下,大幅降低硬件成本。
我们先来看DeepSeek R1量化模型。所谓量化模型,指的是经过了精度压缩之后的模型,这个过程和文件压缩类似,比如用微信传图片,图片太大就会被压缩。
量化会导致模型的精度降低,但运行所需的硬件门槛也会大幅降低。当然量化也是分等级的,DeepSeek R1的模型量化一般分为以下几个等级,分别是Q2、Q3一直到Q8。
其中Q2、Q4、Q8也被称作为INT2、INT4和INT8量化,数值越高代表的保留的精度也越高,模型体积更大、性能更强、运行需要的算力也更大,反之数值越小则代表压缩程度越大,性能更弱、运行所需算力也更少。
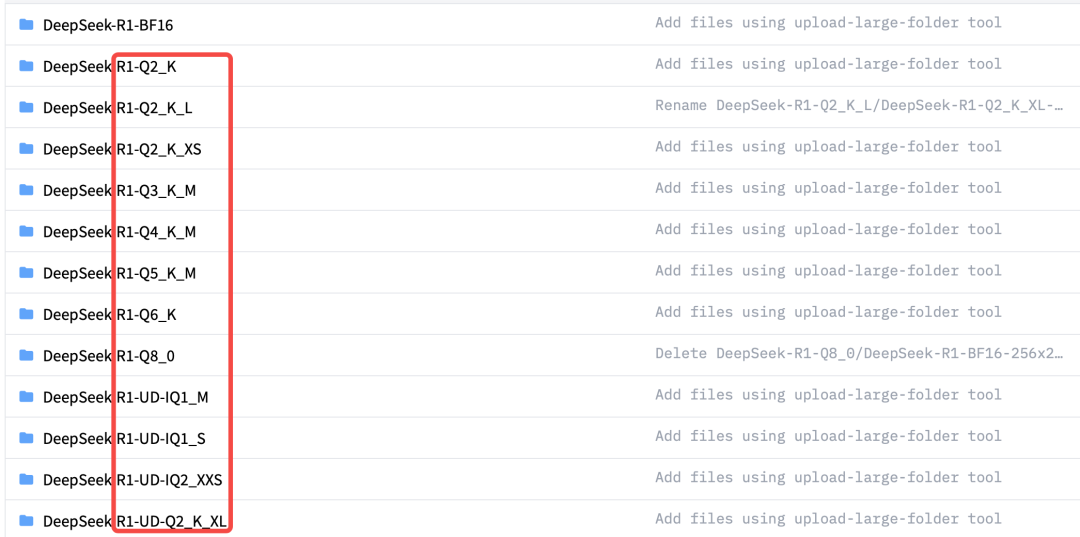
最低Q2_K_M量化模型,仅在双卡A100服务器上即可运行,并且模型性能和响应效率都能得到保障。
而如果是八卡A100单节点服务器,则可以流畅运行Q4_K_M模型,该模型也是目前公认的能够比较好的平衡模型性能与计算效率的量化模型,也是Ollama默认支持的量化模型。
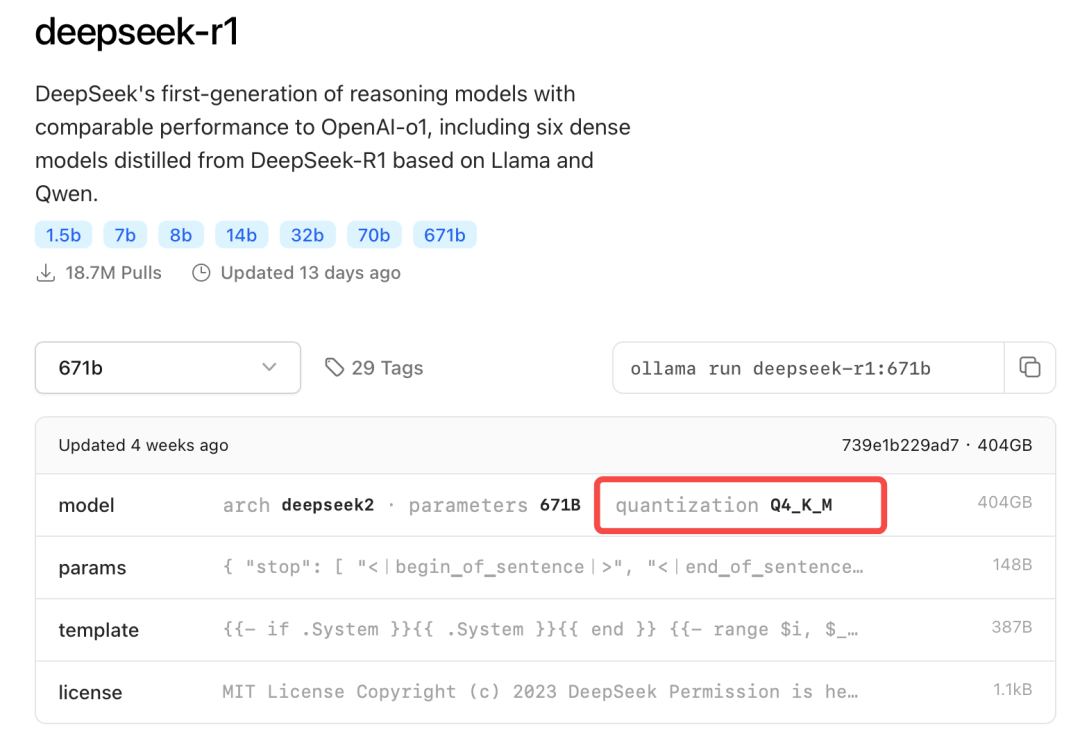
当然,如果还能进一步放宽模型的性能要求,那还可以考虑DeepSeek R1的蒸馏模型组,这组模型是
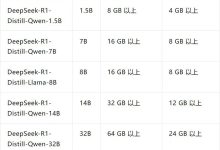
DeepSeek R1蒸馏了Qwen、Llama等模型得到的模型,模型推理能力很强。而且模型尺寸从1.5B到70B不等,可以适配从消费级显卡到服务器级显卡等各类硬件。
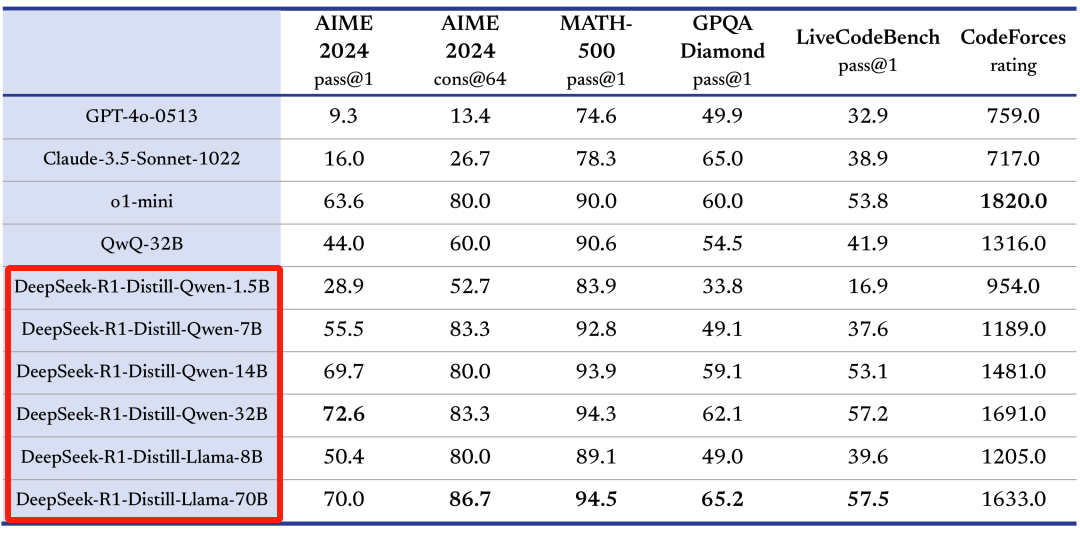
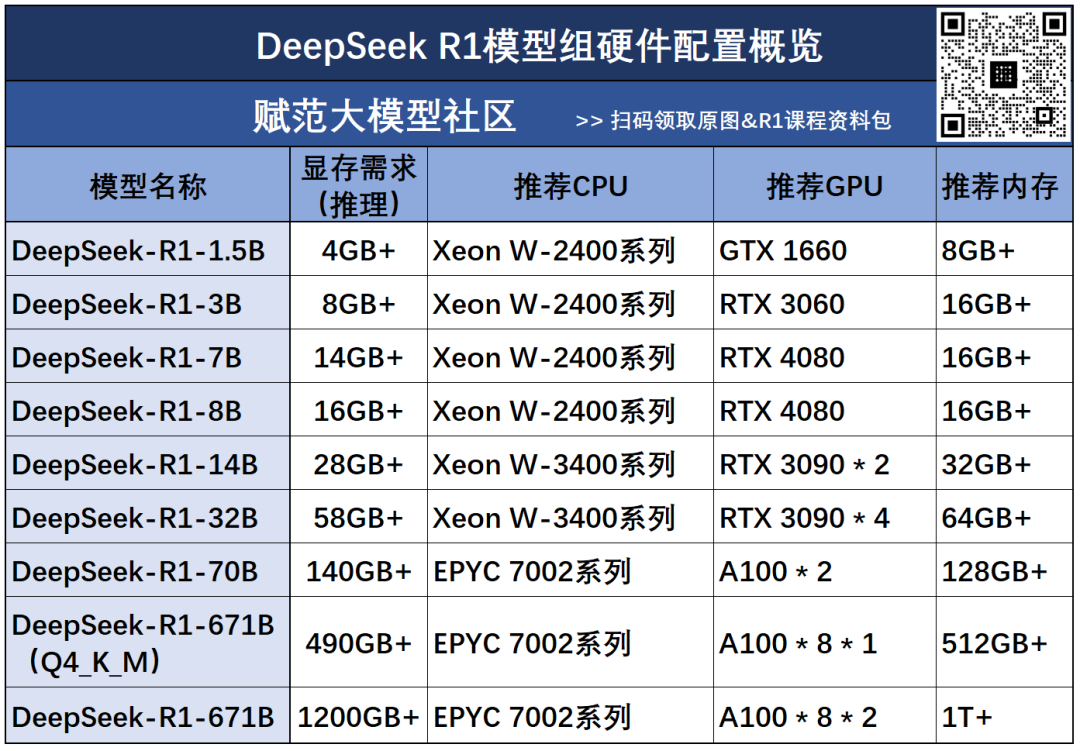
最小的1.5B模型,GTX1660显卡即可运行,编程能力可以达到GPT4o级别,而最大的70B模型,则需要双卡A100服务器才可运行,和DeepSeek R1 Q2量化模型运行硬件条件相当。

详细的R1蒸馏模型运行所需配置如图所示:
当然,如果你既不想在模型性能上让步,同时又希望节省GPU成本,那最后还有一个方案,就是同时借助CPU和GPU进行混合推理。
由于采用了CPU执行计算任务,GPU的负载会大幅降低,整体硬件成本也会下降。但是,毕竟CPU不适合进行深度学习计算,所以模型整体推理速度会很慢,并且无法进行模型训练。
虽然这套方案牺牲了计算速度,但仍然是目前热度最高的低成本部署方案。要了解这套方案背后的玄机?我们要先补充一些基础知识。
其实早在2023年3月,也就是Llama第一代模型开源不久,有一位C语言大神(Georgi Gerganov),在GitHub上发起了一个名为llama.cpp的项目,该项目非常夸张的用C语言编写了一整套深度学习底层张量计算库,极大程度降低了大模型等深度学习算法的计算门槛,并最终使得大模型可以在消费级CPU上运行。
值得一提的是,llama.cpp现在已经成了大模型量化的标准解决方案,前面谈到的Q2、Q4、Q8等模型量化,都是借助llama.cpp完成的。这个神级项目,现在在GitHub上已经斩获了75k stars。
借助llama.cpp,可以使用纯CPU模式来运行DeepSeek R1模型,只不过此时需要大量的内存来加载模型权重,并且运行速度非常慢,不过硬件价格倒是很便宜。
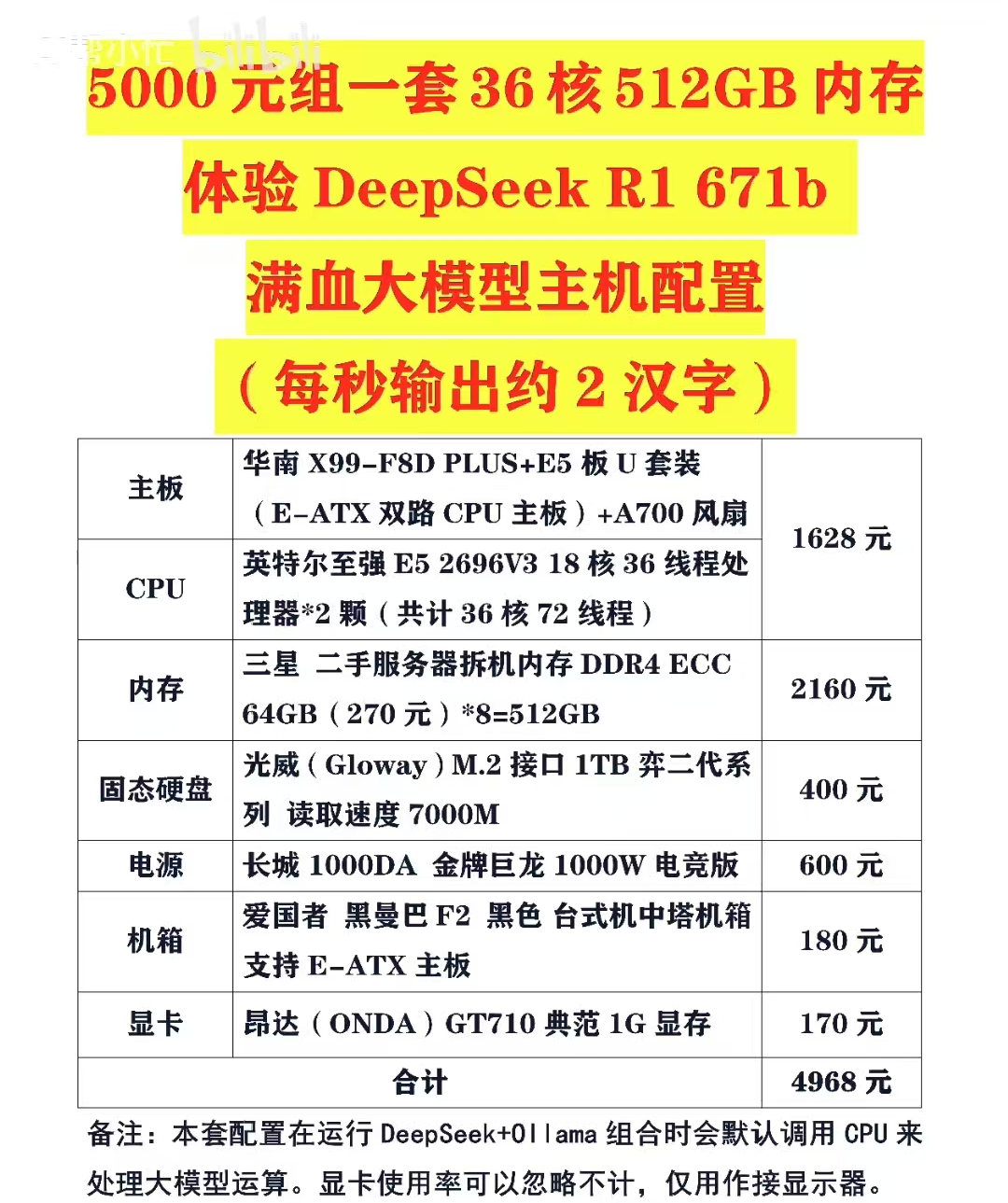
比如网上甚至有500运行DeepSeek R1 Q4_K_M模型的组机方案,只不过采用纯CPU推理模式,每秒只能输出两个字符,而且不支持并发,一个300字的小作文,就得写个2、3分钟。
那能不能在CPU推理基础上,再借助一些GPU能力来加速呢?基于这个思路,清华大学团队和Unsloth团队,分别提出了可以同时借助CPU和GPU进行推理的DeepSeek R1部署方案。
|
|
|


其中,清华大学发起的KTransformers(Quick Transformers)项目,可以借助R1模型的MoE架构特性,将专家模型的权重加载到内存上,并分配CPU完成相关计算工作,同时将MLA/KV Cache加载到GPU上,进而实现CPU+GPU混合推理。
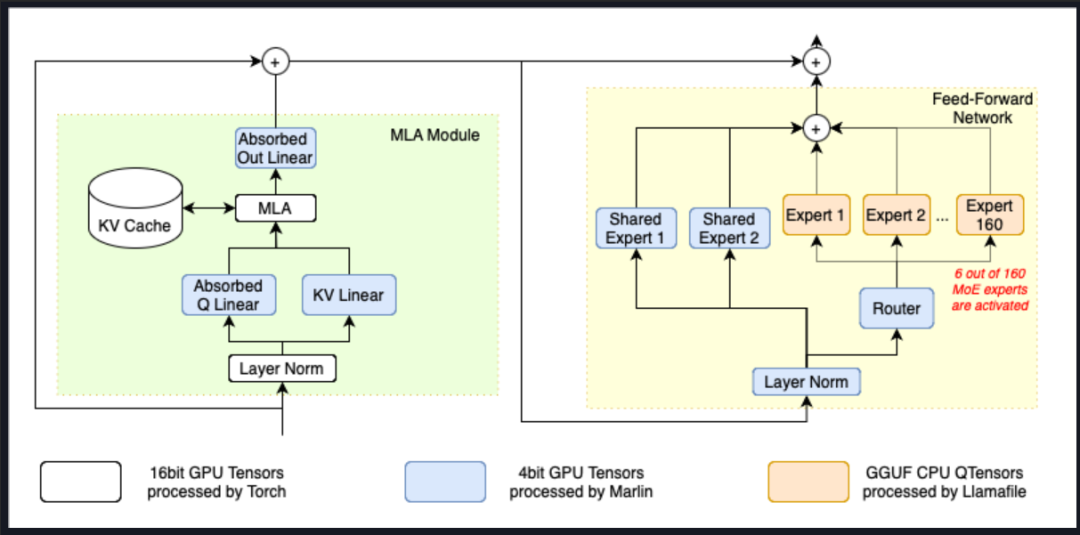
在这个方案中,14G显存+382G内存即可运行DeepSeek R1 Q4_K_M模型。而这套硬件价格,最多不超过5万即可拿下,相比八卡A100服务器,可以说是节省至少百万成本。

不过这套方案最大的问题在于,模型运行速度会大幅受到CPU性能影响,需要4代志强芯片才能达到10个以上token每秒,而且KTransformers对GPU性能挖掘不足,高并发场景下表现乏力,更适合小团队或个人使用。
相比之下,Unsloth提出的动态量化方案会更加综合一些,所谓动态量化的技术,指的是可以围绕模型的不同层,进行不同程度的量化,关键层呢,就量化的少一些,非关键层量化的多一些,最终得到了一组比Q2量化程度更深的模型组,分别是1.58-bit、1.73-bit和2.22-bit模型组。尽管量化程度很深,但实际性能其实并不弱。

此外,Unsloth提供了一套可以把模型权重分别加载到CPU和GPU上的方法,用户可以根据自己实际硬件情况,选择加载若干层模型权重到GPU上,然后剩下的模型权重加载到CPU内存上进行计算。

例如,如果是单卡24G显卡,并且运行1.58bit模型,那么最多可以加载7层模型权重到GPU上,其他的交给CPU来计算。

而如果假设有双卡A100服务器,并且选择运行2.22bit模型,那么就可以将49层加载到GPU上来运行。

并且,加载到GPU上的层数越多,并发量也越大。例如假设运行1.58bit模型,如果把全部的61层权重全都加载到双卡A100服务器上,那么服务器负载将达到140tokens每秒,支持百人并发,并能保持每个人14tokens每秒的响应速度。

很明显,这套方案灵活度更高,也能够更加充分的挖掘GPU性能,从而保障并发量,更适合有一定硬件基础的企业来使用。

总的来看,在这三套低成本高性能部署方案中,

CPU+GPU混合推理应该是性价比最高的方案了,不过这套方案的技术难度却很高,我们团队攻坚克难,为大家提供了完整的零基础保姆级部署流程,这也是全网独家部署教程,大家扫码即可领取。同时相关教学视频可以在我的B站主页上看到。
好了,以上就是DeepSeek R1完整的部署方案介绍。我将不同方案的选配思路,都写在这张思维导图中。

视频的最后,给正在采购硬件的伙伴们提供一份避坑指南。
伴随着DeepSeek R1本地部署需求暴增,也有很多厂商推出了DeepSeek R1服务器,并且有些R1服务器价格简直便宜的离谱,几万块的服务器,就能号称部署R1满血版模型。硬件市场一般不会有天上掉馅饼的好事儿,这个时候我们需要从以下4个方面进行仔细的甄别:
· 确认运行的模型版本:我们要确认到底运行的是哪个R1模型,以及是不是经过量化后的模型或者蒸馏模型;
· 确认硬件型号和运行模式:如果是CPU+GPU混合推理,那4代志强CPU推理性能更强,如果是纯GPU推理,需要确认是图形显卡、如A6000,还是推理训练一体显卡,如A100,如果图形显卡,那未来可能无法进行模型训练和模型微调;
· 确认响应速度和并发量:一般来说单人响应速度在6 tokens每秒属于能够接受的范围,14 tokens每秒属于比较舒服的响应速度。同时还要考虑服务器并发量,也就是假设团队多人使用情况下,能不能保证每人14 tokens每秒。
· 确认下硬件是否全新以及未来保修策略。硬件市场鱼龙混杂,有很多以次充好和翻新的硬件,需要仔细确认硬件情况以及保修策略。
在确认以上基本信息后,可根据实际需求采购硬件。
好了,以上就是本期全部内容。我是九天,如果觉得有用,记得点个「赞」哦!




评论前必须登录!
注册