 网硕互联帮助中心
网硕互联帮助中心目录标题
-
- AlwaysOn
- 语句
-
- 代码解释:
- 1. `sys.dm_hadr_database_replica_states` 视图字段详细解释及官网链接
-
- 官网链接
- 字段解释
- 2. `sys.availability_replicas` 视图字段详细解释及官网链接
-
- 官网链接
- 字段解释
- 查看视图的创建语句
-
- 方法一:使用 SQL Server Management Studio (SSMS)
- 方法二:使用系统视图 `sys.sql_modules`
-
- 代码解释:
- 方法三:使用 `sp_helptext` 存储过程
-
- 注意事项:
- `[dbo].[ha_status]`
-
- 1. 视图基本信息
- 2. 视图定义
- 3. 选择列及计算列
- 4. 表连接
- 总结
- `[master].[dbo].[ha_status]` 的全面解释
-
- 整体概述
- 1. 查询语句部分
-
- 各部分解释
- 2. 视图 `[ha_status]` 各列详细解释
-
- 标识信息
- 故障转移相关
- 副本角色与模式
- 恢复时间与性能指标
- 同步与状态信息
- 其他信息
- seeding
-
- Seeding 的主要作用
- 常见的 Seeding 状态及含义
-
- 1. `NOT_STARTED`
- 2. `IN_PROGRESS`
- 3. `COMPLETED`
- 4. `FAILED`
- 5. `CANCELLED`
- 查看 Seeding 状态的方法
-
- 使用系统视图 `sys.dm_hadr_automatic_seeding`
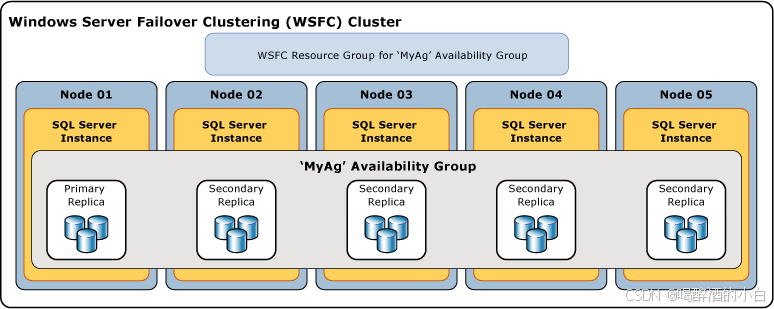
AlwaysOn
SQL Server AlwaysOn通常不支持真正意义上的多主模式,主要以主从(主副本和辅助副本)结构为主,但在某些特定场景和配置下有一些类似多主的特性或功能变体,以下是具体分析:
- 基本架构与原理
- AlwaysOn的核心是基于数据库镜像和日志传送技术,主要支持主从架构。在这种架构中,主副本负责处理所有的读写操作,而辅助副本处于只读状态,主要用于数据冗余、故障转移和报表等辅助功能。辅助副本通过接收主副本发送的日志流来保持数据的同步。
- 相关功能与限制
- 可读辅助副本:在AlwaysOn中,可以将辅助副本配置为可读,允许在辅助副本上执行一些查询操作,分担部分读压力。但这并不等同于多主模式,因为辅助副本上的读写操作受到严格限制,仍然不能作为独立的主节点进行写操作。
- 可用性组侦听器与多实例:虽然可以通过可用性组侦听器来实现多个实例的切换,但在任何时刻,只有一个主副本能够接受写操作,其他副本都是用于故障转移和数据同步的辅助角色,并不是真正的多主并行写入。
- 特殊情况与实验性支持
- 在Azure SQL Database等云环境下的某些特殊配置中,有类似于“多主”的功能,如Azure SQL Database的弹性池中的数据库可以在一定程度上实现跨区域的多主写入,但这与传统意义上的AlwaysOn本地部署的多主支持有很大区别,且是在特定的云环境和功能集下实现的。
Linux 上的 SQL Server 的可用性组 AlwaysOn
语句
sys.dm_hadr_database_replica_states 和 sys.availability_replicas 视图关联起来,
SELECT
ar.replica_id,
ar.replica_server_name,
ar.endpoint_url,
ar.failover_mode_desc,
ar.availability_mode_desc,
drs.database_id,
drs.group_database_id,
drs.is_local,
drs.is_primary_replica,
drs.synchronization_state,
drs.synchronization_state_desc,
drs.is_commit_participant,
drs.synchronization_health,
drs.synchronization_health_desc,
drs.database_state,
drs.database_state_desc,
drs.is_suspended,
drs.suspend_reason,
drs.suspend_reason_desc,
drs.recovery_lsn,
drs.truncation_lsn,
drs.last_sent_lsn,
drs.last_sent_time,
drs.last_received_lsn,
drs.last_received_time,
drs.last_hardened_lsn,
drs.last_hardened_time,
drs.last_redone_lsn,
drs.last_redone_time,
drs.log_send_queue_size,
drs.log_send_rate,
drs.redo_queue_size,
drs.redo_rate,
drs.filestream_send_rate,
drs.end_of_log_lsn,
drs.last_commit_lsn,
drs.last_commit_time,
drs.low_water_mark_for_ghosts,
drs.secondary_lag_seconds,
drs.quorum_commit_lsn,
drs.quorum_commit_time
FROM
sys.availability_replicas ar
JOIN
sys.dm_hadr_database_replica_states drs ON ar.replica_id = drs.replica_id;
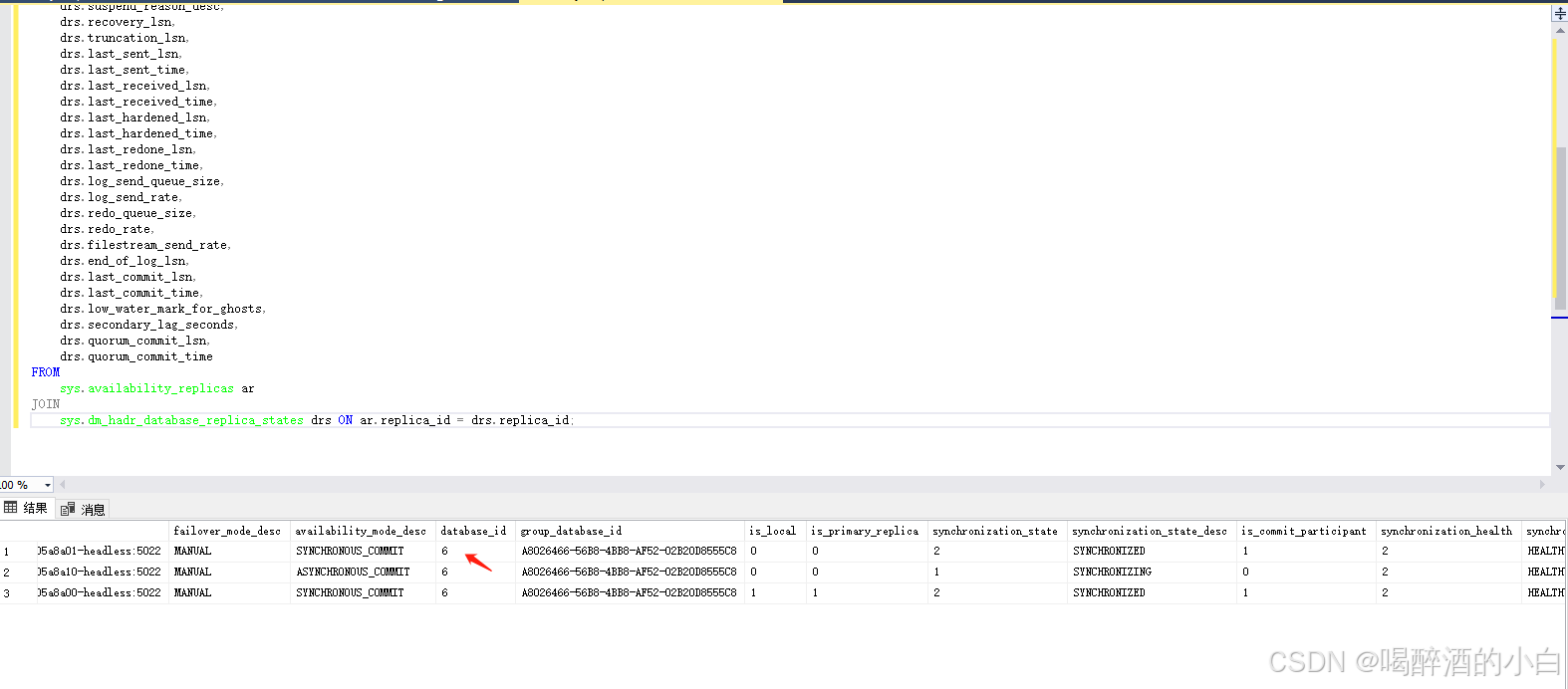
SELECT DB_NAME(database_id) AS 'database', synchronization_state_desc FROM sys.dm_hadr_database_replica_states;
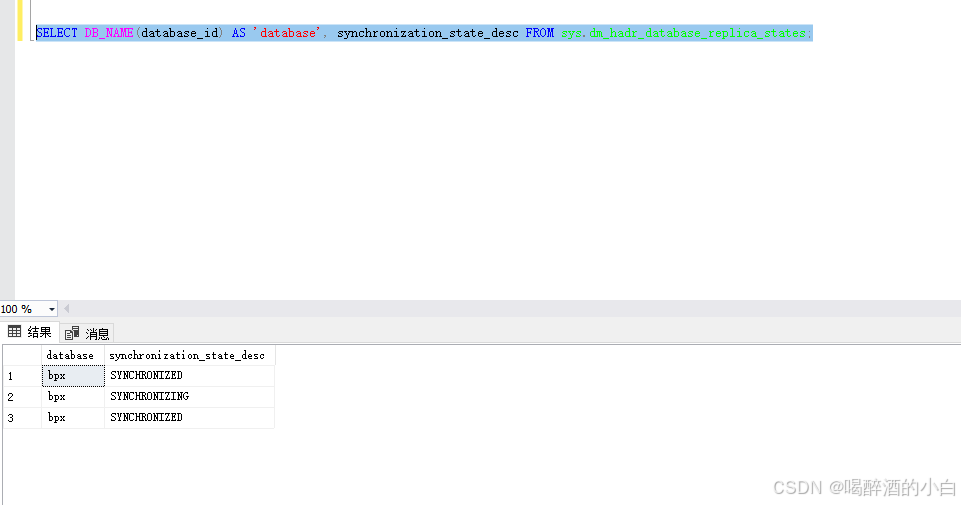
代码解释:
sys.availability_replicas 视图:
- 该视图存储了 Always On 可用性组中每个副本的元数据信息。
- replica_id:副本的唯一标识符。
- replica_server_name:副本所在的 SQL Server 实例名称。
- endpoint_url:副本的端点 URL,用于副本之间的通信。
- failover_mode_desc:副本的故障转移模式描述,例如自动故障转移、手动故障转移等。
- availability_mode_desc:副本的可用性模式描述,如同步提交、异步提交。
sys.dm_hadr_database_replica_states 视图:
- 这是一个动态管理视图,提供了关于可用性组中数据库副本的实时状态信息。
- 包含了你之前展示的众多列,如 database_id、is_local、is_primary_replica、同步状态相关列、日志序列号相关列等。
JOIN 操作:
- 通过 JOIN 语句将 sys.availability_replicas 视图和 sys.dm_hadr_database_replica_states 视图根据 replica_id 进行关联。
- 这样可以把副本的元数据信息(如副本所在服务器名称)和数据库副本的实时状态信息结合起来,让你既能确认 replica_id 对应的具体副本,又能查看该副本上数据库的详细状态。
1. sys.dm_hadr_database_replica_states 视图字段详细解释及官网链接
官网链接
sys.dm_hadr_database_replica_states (Transact – SQL)
字段解释
- replica_id:可用性副本的唯一标识符,对应 sys.availability_replicas 中的 replica_id,用于关联两个视图。
- group_id:可用性组的唯一标识符。
- database_id:数据库的标识符,标识该副本中的数据库。
- group_database_id:可用性组内数据库的唯一标识符。
- is_local:指示该副本是否为本地副本。值为 1 表示是本地副本,0 表示不是。
- is_primary_replica:指示该副本是否为主副本。1 表示主副本,0 表示辅助副本。
- synchronization_state:数据库副本的同步状态的数字代码。例如 1 表示 SYNCHRONIZING(正在同步),2 表示 SYNCHRONIZED(已同步)等。
- synchronization_state_desc:同步状态的文本描述,与 synchronization_state 代码对应。
- is_commit_participant:指示该副本是否参与事务提交。1 表示参与,0 表示不参与。
- synchronization_health:同步健康状态的数字代码。
- synchronization_health_desc:同步健康状态的文本描述。
- database_state:数据库状态的数字代码。
- database_state_desc:数据库状态的文本描述。
- is_suspended:指示该副本是否已暂停。1 表示暂停,0 表示未暂停。
- suspend_reason:暂停原因的数字代码。
- suspend_reason_desc:暂停原因的文本描述。
- recovery_lsn:恢复日志序列号,指示数据库恢复的起始点。
- truncation_lsn:截断日志序列号,指示可以截断日志的位置。
- last_sent_lsn:主副本上最后发送到辅助副本的日志序列号。
- last_sent_time:主副本上最后发送日志的时间。
- last_received_lsn:辅助副本上最后接收到的日志序列号。
- last_received_time:辅助副本上最后接收日志的时间。
- last_hardened_lsn:辅助副本上最后持久化到磁盘的日志序列号。
- last_hardened_time:辅助副本上最后持久化日志到磁盘的时间。
- last_redone_lsn:辅助副本上最后重做的日志序列号。
- last_redone_time:辅助副本上最后重做日志的时间。
- log_send_queue_size:日志发送队列的大小(以字节为单位)。
- log_send_rate:日志发送速率(以字节/秒为单位)。
- redo_queue_size:重做队列的大小(以字节为单位)。
- redo_rate:重做速率(以字节/秒为单位)。
- filestream_send_rate:FileStream 数据的发送速率(以字节/秒为单位)。
- end_of_log_lsn:日志末尾的日志序列号。
- last_commit_lsn:最后提交事务的日志序列号。
- last_commit_time:最后提交事务的时间。
- low_water_mark_for_ghosts:幽灵记录的低水位标记。
- secondary_lag_seconds:辅助副本相对于主副本的延迟秒数。
- quorum_commit_lsn:法定提交的日志序列号。
- quorum_commit_time:法定提交的时间。
2. sys.availability_replicas 视图字段详细解释及官网链接
官网链接
sys.availability_replicas (Transact – SQL)
字段解释
- replica_id:可用性副本的唯一标识符,用于和 sys.dm_hadr_database_replica_states 视图进行关联。
- group_id:可用性组的唯一标识符。
- replica_metadata_id:副本的元数据标识符。
- replica_server_name:承载该可用性副本的 SQL Server 实例的名称。
- owner_sid:副本所有者的安全标识符。
- endpoint_url:副本的端点 URL,用于副本之间的通信。
- availability_mode:可用性模式的数字代码,例如 1 表示同步提交,2 表示异步提交。
- availability_mode_desc:可用性模式的文本描述。
- failover_mode:故障转移模式的数字代码,例如 1 表示自动故障转移,2 表示手动故障转移。
- failover_mode_desc:故障转移模式的文本描述。
- session_timeout:会话超时时间(以秒为单位)。
- primary_role_allow_connections:主副本允许的连接类型的数字代码。
- primary_role_allow_connections_desc:主副本允许的连接类型的文本描述。
- secondary_role_allow_connections:辅助副本允许的连接类型的数字代码。
- secondary_role_allow_connections_desc:辅助副本允许的连接类型的文本描述。
- create_date:副本创建的日期和时间。
- modify_date:副本最后修改的日期和时间。
- backup_priority:备份优先级,值越高表示越优先进行备份。
- read_only_routing_url:只读路由的 URL。
- seeding_mode:种子设定模式的数字代码。
- seeding_mode_desc:种子设定模式的文本描述。
查看视图的创建语句
在 SQL Server 中,有多种方法可以查看视图的创建语句,下面为你详细介绍:
方法一:使用 SQL Server Management Studio (SSMS)
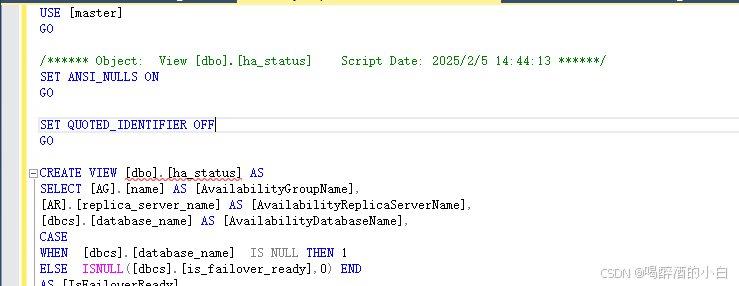
方法二:使用系统视图 sys.sql_modules
可以通过查询 sys.sql_modules 系统视图来获取视图的定义脚本。以下是具体的 SQL 示例:
— 假设要查看的视图名为 YourViewName,数据库名为 YourDatabaseName
USE master;
SELECT
sm.definition
FROM
sys.sql_modules sm
JOIN
sys.objects o ON sm.object_id = o.object_id
WHERE
o.type = 'V' — 'V' 表示视图
AND o.name = 'ha_status';
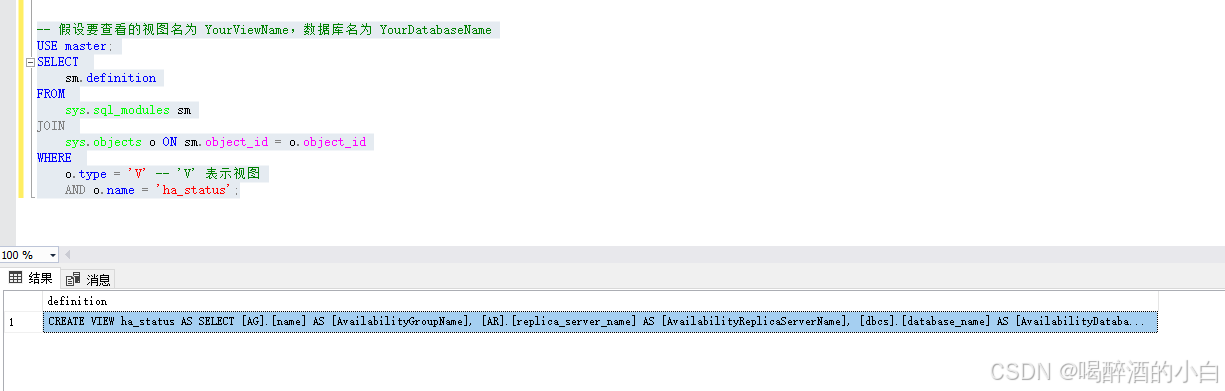
代码解释:
- sys.sql_modules 视图存储了数据库中所有模块(包括视图、存储过程、函数等)的定义文本。
- sys.objects 视图包含了数据库中所有对象的元数据信息,通过 object_id 将两个视图关联起来。
- o.type = 'V' 用于筛选出类型为视图的对象。
- o.name = 'YourViewName' 用于指定要查看的具体视图名称。
方法三:使用 sp_helptext 存储过程
sp_helptext 是 SQL Server 提供的一个系统存储过程,可用于查看对象的定义文本,包括视图。示例如下:
— 假设要查看的视图名为 YourViewName
EXEC sp_helptext 'ha_status';
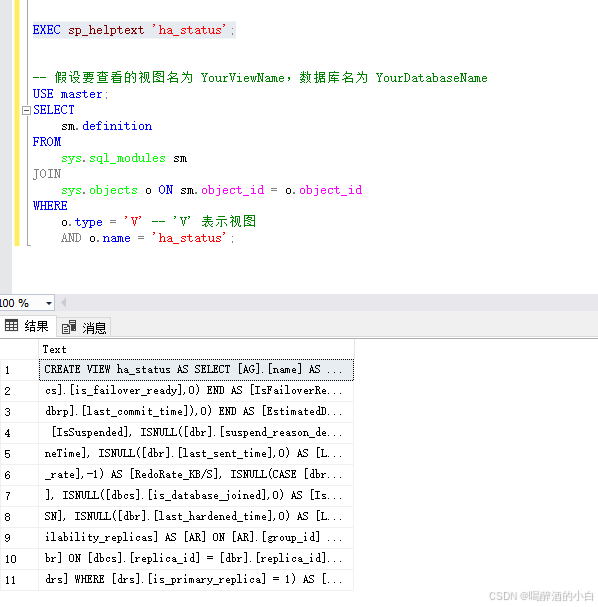
注意事项:
- 如果视图所在的数据库不是当前默认数据库,需要在视图名称前加上数据库名和架构名,例如 EXEC sp_helptext 'YourDatabaseName.dbo.YourViewName';
- sp_helptext 会将视图的定义文本逐行显示,如果定义较长,可能会分行显示。
通过以上方法,你可以方便地查看 SQL Server 中视图的创建语句。
[dbo].[ha_status]
以下是对这个视图 [dbo].[ha_status] 创建语句的详细解释:
1. 视图基本信息
USE [master]
GO
/****** Object: View [dbo].[ha_status] Script Date: 2025/2/5 14:44:13 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER OFF
GO
- USE [master]:指定当前使用的数据库为 master 数据库。
- SET ANSI_NULLS ON:启用 ANSI 空值处理规则,即当比较操作涉及 NULL 值时,结果为 NULL。
- SET QUOTED_IDENTIFIER OFF:指定是否将双引号字符解释为分隔标识符或字符串文字。这里设置为 OFF 表示不严格遵循 SQL-92 标准,双引号可以用于字符串文字。
2. 视图定义
CREATE VIEW [dbo].[ha_status] AS
这行代码创建了一个名为 [dbo].[ha_status] 的视图,其中 dbo 是视图所属的架构。
3. 选择列及计算列
SELECT
[AG].[name] AS [AvailabilityGroupName],
[AR].[replica_server_name] AS [AvailabilityReplicaServerName],
[dbcs].[database_name] AS [AvailabilityDatabaseName],
CASE
WHEN [dbcs].[database_name] IS NULL THEN 1
ELSE ISNULL([dbcs].[is_failover_ready],0)
END AS [IsFailoverReady],
ISNULL([arstates].[role_desc],3) AS [ReplicaRole],
[AR].[availability_mode_desc] AS [AvailabilityMode],
CASE [dbcs].[is_failover_ready]
WHEN 1
THEN 0
ELSE ISNULL(DATEDIFF([ss],[dbr].[last_commit_time],[dbrp].[last_commit_time]),0)
END AS [EstimatedDataLoss_(Seconds)],
ISNULL(CASE [dbr].[redo_rate]
WHEN 0
THEN –1
ELSE CAST([dbr].[redo_queue_size] AS FLOAT) / [dbr].[redo_rate]
END,–1) AS [EstimatedRecoveryTime_(Seconds)],
ISNULL([dbr].[is_suspended],0) AS [IsSuspended],
ISNULL([dbr].[suspend_reason_desc],'-') AS [SuspendReason],
ISNULL([dbr].[synchronization_state_desc],0) AS [SynchronizationState],
ISNULL([dbr].[last_received_time],0) AS [LastReceivedTime],
ISNULL([dbr].[last_redone_time],0) AS [LastRedoneTime],
ISNULL([dbr].[last_sent_time],0) AS [LastSentTime],
ISNULL([dbr].[log_send_queue_size],–1) AS [LogSendQueueSize],
ISNULL([dbr].[log_send_rate],–1) AS [LogSendRate_KB/S],
ISNULL([dbr].[redo_queue_size],–1) AS [RedoQueueSize_KB],
ISNULL([dbr].[redo_rate],–1) AS [RedoRate_KB/S],
ISNULL(CASE [dbr].[log_send_rate]
WHEN 0
THEN –1
ELSE CAST([dbr].[log_send_queue_size] AS FLOAT) / [dbr].[log_send_rate]
END,–1) AS [SynchronizationPerformance],
ISNULL([dbr].[filestream_send_rate],–1) AS [FileStreamSendRate],
ISNULL([dbcs].[is_database_joined],0) AS [IsJoined],
[arstates].[is_local] AS [IsLocal],
ISNULL([dbr].[last_commit_lsn],0) AS [LastCommitLSN],
ISNULL([dbr].[last_commit_time],0) AS [LastCommitTime],
ISNULL([dbr].[last_hardened_lsn],0) AS [LastHardenedLSN],
ISNULL([dbr].[last_hardened_time],0) AS [LastHardenedTime],
ISNULL([dbr].[last_received_lsn],0) AS [LastReceivedLSN],
ISNULL([dbr].[last_redone_lsn],0) AS [LastRedoneLSN]
这部分代码定义了视图返回的列,包括从不同系统表中选取的列以及一些计算列:
- CASE 语句用于根据不同条件进行值的计算和判断,例如 [IsFailoverReady] 和 [EstimatedDataLoss_(Seconds)] 列。
- ISNULL 函数用于处理可能的 NULL 值,当列值为 NULL 时,使用指定的默认值。
- 计算列如 [EstimatedRecoveryTime_(Seconds)] 和 [SynchronizationPerformance] 是通过对其他列进行数学运算得到的。
4. 表连接
FROM [master].[sys].[availability_groups] AS [AG]
LEFT JOIN [master].[sys].[availability_replicas] AS [AR] ON [AR].[group_id] = [AG].[group_id]
LEFT JOIN [master].[sys].[dm_hadr_database_replica_cluster_states] AS [dbcs] ON [dbcs].[replica_id] = [AR].[replica_id]
LEFT OUTER JOIN [master].[sys].[dm_hadr_database_replica_states] AS [dbr] ON [dbcs].[replica_id] = [dbr].[replica_id]
AND [dbcs].[group_database_id] = [dbr].[group_database_id]
LEFT OUTER JOIN (
SELECT
[drs].[database_id],
[drs].[replica_id],
[drs].[last_commit_time]
FROM [master].[sys].[dm_hadr_database_replica_states] AS [drs]
WHERE [drs].[is_primary_replica] = 1
) AS [dbrp] ON [dbr].[database_id] = [dbrp].[database_id]
LEFT JOIN [master].[sys].[dm_hadr_availability_replica_states] AS [arstates] ON [arstates].[replica_id] = [AR].[replica_id];
这部分代码通过多个 LEFT JOIN 操作将不同的系统表连接起来,以获取所需的数据:
- [master].[sys].[availability_groups]:包含可用性组的信息。
- [master].[sys].[availability_replicas]:包含可用性副本的信息。
- [master].[sys].[dm_hadr_database_replica_cluster_states]:包含数据库副本在集群中的状态信息。
- [master].[sys].[dm_hadr_database_replica_states]:包含数据库副本的详细状态信息。
- [master].[sys].[dm_hadr_availability_replica_states]:包含可用性副本的状态信息。
子查询 [dbrp] 用于筛选出主副本的 last_commit_time 信息,以便计算数据丢失估计时间。
总结
这个视图 [dbo].[ha_status] 主要用于汇总 SQL Server Always On 可用性组的相关状态信息,包括可用性组名称、副本服务器名称、数据库名称、故障转移准备情况、数据丢失估计、恢复时间估计、同步状态等,方便管理员监控和管理可用性组。
[master].[dbo].[ha_status] 的全面解释
以下是对这个查询语句以及相关视图 [master].[dbo].[ha_status] 的全面解释:
整体概述
此查询语句的作用是从 [master].[dbo].[ha_status] 视图中选取前 1000 条记录,获取 SQL Server Always On 可用性组的详细状态信息,这些信息对于监控和管理可用性组的健康状况、性能表现以及故障转移能力等方面具有重要意义。
1. 查询语句部分
SELECT TOP (1000)
[AvailabilityGroupName],
[AvailabilityReplicaServerName],
[AvailabilityDatabaseName],
[IsFailoverReady],
[ReplicaRole],
[AvailabilityMode],
[EstimatedDataLoss_(Seconds)],
[EstimatedRecoveryTime_(Seconds)],
[IsSuspended],
[SuspendReason],
[SynchronizationState],
[LastReceivedTime],
[LastRedoneTime],
[LastSentTime],
[LogSendQueueSize],
[LogSendRate_KB/S],
[RedoQueueSize_KB],
[RedoRate_KB/S],
[SynchronizationPerformance],
[FileStreamSendRate],
[IsJoined],
[IsLocal],
[LastCommitLSN],
[LastCommitTime],
[LastHardenedLSN],
[LastHardenedTime],
[LastReceivedLSN],
[LastRedoneLSN]
FROM [master].[dbo].[ha_status];
各部分解释
- SELECT TOP (1000):指定查询结果仅返回前 1000 条记录。当视图中的数据量较大时,使用 TOP 关键字可以限制返回的数据量,避免返回过多数据导致性能问题或显示不便。
- 列选择:明确列出了要从视图中选取的列,这些列涵盖了可用性组、副本、数据库的各种状态和性能指标。
- FROM [master].[dbo].[ha_status]:指定查询的数据来源为 [master] 数据库中 [dbo] 架构下的 [ha_status] 视图。
2. 视图 [ha_status] 各列详细解释
标识信息
- AvailabilityGroupName:可用性组的名称,用于唯一标识一个 Always On 可用性组。通过该名称可以区分不同的可用性组,方便管理员对多个可用性组进行管理和监控。
- AvailabilityReplicaServerName:可用性副本所在的 SQL Server 实例名称。每个可用性组可以包含多个副本,分布在不同的服务器上,该列用于标识副本所在的具体服务器。
- AvailabilityDatabaseName:可用性组中数据库的名称,表明该记录所涉及的具体数据库。
故障转移相关
- IsFailoverReady:表示该数据库副本是否已准备好进行故障转移。值为 1 表示准备好,0 表示未准备好。此指标对于评估可用性组的高可用性至关重要,当主副本出现故障时,只有准备好的辅助副本才能顺利接管工作。
- EstimatedDataLoss_(Seconds):估计的数据丢失时间(以秒为单位)。在故障转移过程中,如果辅助副本与主副本之间存在数据延迟,可能会导致部分数据丢失,该指标用于估算可能丢失的数据对应的时间范围。
副本角色与模式
- ReplicaRole:副本的角色,如主副本、辅助副本等。不同的角色具有不同的功能和职责,主副本负责处理读写操作,辅助副本则用于数据备份和故障转移。
- AvailabilityMode:可用性模式,例如同步提交或异步提交。同步提交模式下,主副本在确认事务提交之前会等待辅助副本将事务日志写入磁盘,确保数据的一致性;异步提交模式则不等待,性能较高但可能存在数据丢失的风险。
恢复时间与性能指标
- EstimatedRecoveryTime_(Seconds):估计的恢复时间(以秒为单位),表示辅助副本在发生故障后恢复到可用状态所需的大致时间。该指标可以帮助管理员评估故障恢复的效率和影响范围。
- LogSendQueueSize:日志发送队列的大小,反映了主副本等待发送到辅助副本的事务日志的数量。队列过大可能表示网络延迟或辅助副本处理能力不足。
- LogSendRate_KB/S:日志发送速率(以 KB/秒为单位),衡量主副本向辅助副本发送事务日志的速度。该指标可以反映网络带宽和系统性能对日志传输的影响。
- RedoQueueSize_KB:重做队列的大小,即辅助副本等待重做的事务日志的数量。队列过大可能导致辅助副本与主副本之间的延迟增加。
- RedoRate_KB/S:重做速率(以 KB/秒为单位),表示辅助副本重做事务日志的速度。该指标反映了辅助副本处理日志的能力。
- SynchronizationPerformance:同步性能指标,通过日志发送队列大小和日志发送速率计算得出,用于评估主副本和辅助副本之间的同步效率。
同步与状态信息
- IsSuspended:表示该数据库副本是否已暂停。值为 1 表示暂停,0 表示正常运行。暂停副本可能是由于维护、故障排查等原因。
- SuspendReason:如果副本已暂停,该列显示暂停的原因,方便管理员了解情况并采取相应的措施。
- SynchronizationState:副本的同步状态,如正在同步、已同步等。同步状态反映了副本与主副本之间的数据一致性程度。
- LastReceivedTime:辅助副本最后一次接收到主副本发送的事务日志的时间,用于监控日志接收的及时性。
- LastRedoneTime:辅助副本最后一次重做事务日志的时间,结合 LastReceivedTime 可以分析辅助副本处理日志的延迟情况。
- LastSentTime:主副本最后一次发送事务日志的时间,用于监控主副本的日志发送情况。
其他信息
- FileStreamSendRate:FileStream 数据的发送速率,对于使用 FileStream 功能存储大型二进制数据的数据库,该指标可以反映数据传输的性能。
- IsJoined:表示数据库是否已加入到可用性组中。值为 1 表示已加入,0 表示未加入。
- IsLocal:表示该副本是否为本地副本。
- LastCommitLSN:最后提交事务的日志序列号(LSN),用于标识事务的顺序和位置。
- LastCommitTime:最后提交事务的时间。
- LastHardenedLSN:最后持久化到磁盘的日志序列号。
- LastHardenedTime:最后持久化日志到磁盘的时间。
- LastReceivedLSN:最后接收到的日志序列号。
- LastRedoneLSN:最后重做的日志序列号。
通过这些信息,管理员可以全面了解 Always On 可用性组的运行状态,及时发现潜在的问题并采取相应的措施,确保数据库的高可用性和数据的一致性。
seeding
在 SQL Server Always On 可用性组的上下文中,“seeding”(种子设定)是将主副本上的数据库数据初始复制到辅助副本的过程。Seeding 状态反映了这个数据初始化过程的当前情况。下面为你详细介绍相关内容:
Seeding 的主要作用
在创建新的辅助副本或者将新数据库加入到可用性组时,需要将主副本上的数据和日志文件复制到辅助副本上,让辅助副本与主副本的数据保持一致,以便后续进行正常的数据同步和故障转移。Seeding 提供了一种自动化、高效的方式来完成这个初始数据复制过程。
常见的 Seeding 状态及含义
1. NOT_STARTED
- 含义:种子设定过程尚未开始。这可能是因为管理员还没有触发种子设定操作,或者正在等待必要的条件满足,例如网络连接、权限等。
- 可能的原因:
- 手动种子设定模式下,管理员还未执行相关的种子设定命令。
- 自动种子设定模式下,可能存在一些先决条件未满足,如端点配置不正确、防火墙阻止了通信等。
2. IN_PROGRESS
- 含义:种子设定过程正在进行中。此时,主副本正在将数据库的数据和日志文件复制到辅助副本。
- 监控要点:可以通过查看相关的系统视图和性能指标来监控种子设定的进度,如 sys.dm_hadr_automatic_seeding 视图中的 transfer_rate_bytes_per_second 列可以显示当前的数据传输速率,total_data_bytes 和 bytes_sent 列可以用于计算传输进度。
3. COMPLETED
- 含义:种子设定过程已成功完成。辅助副本已经接收到主副本上的所有数据和日志文件,并且数据处于一致状态,可以开始正常的同步过程。
- 后续操作:种子设定完成后,辅助副本会开始与主副本进行日志同步,以保持数据的实时一致性。
4. FAILED
- 含义:种子设定过程失败。可能是由于各种原因导致复制过程中断,如网络故障、磁盘空间不足、权限问题等。
- 排查方法:可以查看 sys.dm_hadr_automatic_seeding 视图中的 failure_message 列,获取详细的失败信息,根据错误信息进行相应的排查和修复。
5. CANCELLED
- 含义:种子设定过程被手动取消。管理员可以在种子设定过程中根据需要取消操作。
- 后续处理:如果需要重新进行种子设定,需要重新触发种子设定操作。
查看 Seeding 状态的方法
使用系统视图 sys.dm_hadr_automatic_seeding
SELECT
ag.name AS availability_group_name,
ar.replica_server_name,
ads.*
FROM
sys.dm_hadr_automatic_seeding ads
JOIN
sys.availability_replicas ar ON ads.ag_replica_id = ar.replica_id
JOIN
sys.availability_groups ag ON ar.group_id = ag.group_id;
这个查询可以获取每个可用性组和副本的种子设定状态信息,帮助管理员监控和管理种子设定过程。
通过了解 Seeding 状态,管理员可以及时发现并解决种子设定过程中出现的问题,确保可用性组的顺利部署和运行。



评论前必须登录!
注册